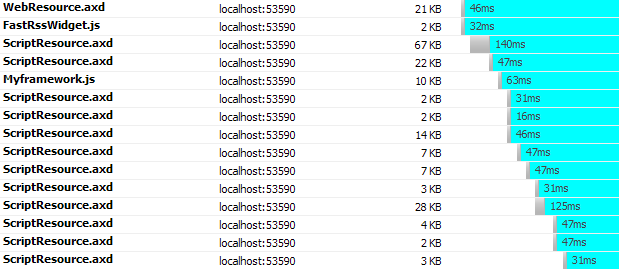
Generally we put static content (images, css, js) of our website
inside the same web project. Thus they get downloaded from the same
domain like www.dropthings.com. There are three
problems in this approach:
- They occupy connections on the same domain www.dropthings.com and thus other
important calls like Web service call do not get a chance to happen
earlier as browser can only make two simultaneous connections per
domain. - If you are using ASP.NET Forms Authentication, then you have
that gigantic Forms Authentication cookie being sent with every
single request on www.dropthings.com. This cookie
gets sent for all images, CSS and JS files, which has no use for
the cookie. Thus it wastes upload bandwidth and makes every request
slower. Upload bandwidth is very limited for users compared to
download bandwidth. Generally users with 1Mbps download speed has
around 128kbps upload speed. So, adding another 100 bytes on the
request for the unnecessary cookie results in delay in sending the
request and thus increases your site load time and the site feels
slow to respond. - It creates enormous IIS Logs as it records the cookies for each
static content request. Moreover, if you are using Google Analytics
to track hits to your site, it issues four big cookies that gets
sent for each and every image, css and js files resulting in slower
requests and even larger IIS log entries.
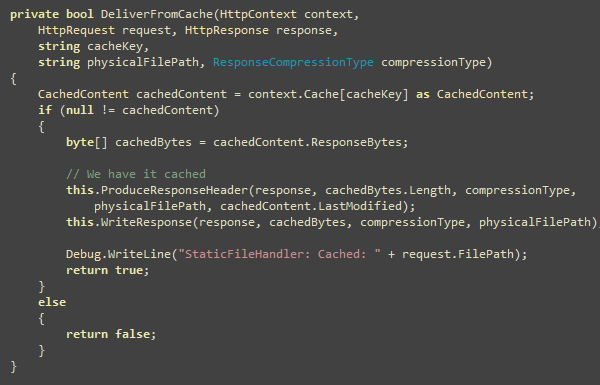
Let’s see the first problem, browser’s two connection limit. See
what happens when content download using two HTTP requests in
parallel:
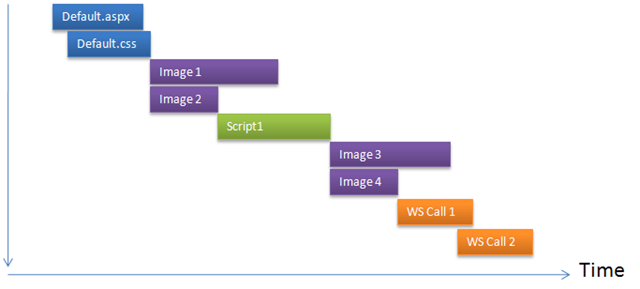
This figure shows only two files are downloaded in parallel. All
the hits are going to the same domain e.g. www.dropthings.com. As you see,
only two call can execute at the same time. Moreover, due to
browser’s way of handling script tags, once a script is being
downloaded, browser does not download anything else until the
script has downloaded and executed.
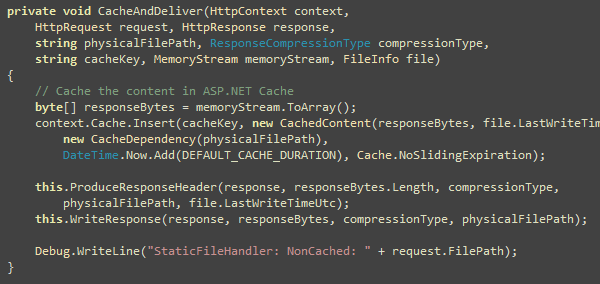
Now, if we can download the images from different domain, which
allows browser to open another two simultaneous connections, then
the page loads a lot faster:
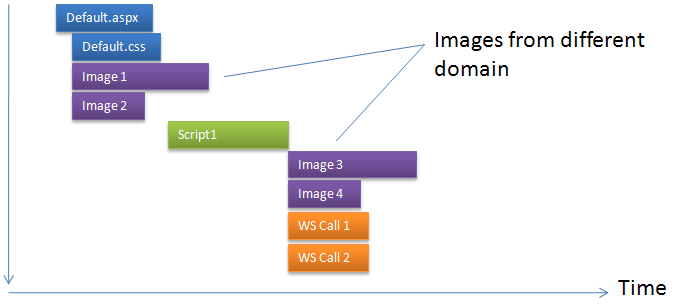
You see, the total page downloads 40% faster. Here only the
images are downloaded from a different domain e.g.
“s.dropthings.com”, thus the calls for the script, CSS and
webservices still go to main domain e.g. www.dropthings.com
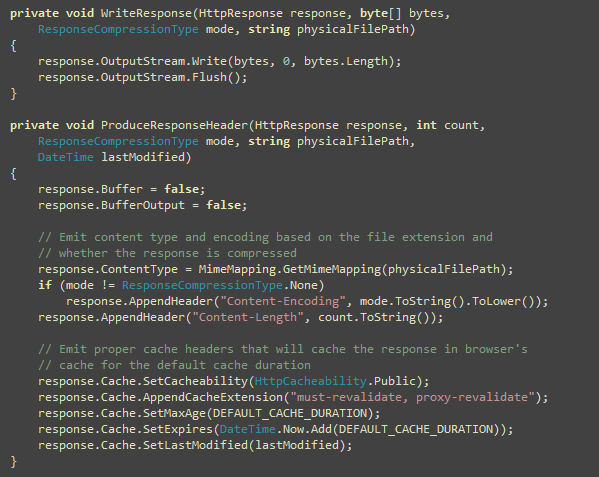
The second problem for loading static content from same domain
is the gigantic forms authentication cookie or any other cookie
being registered on the main domain e.g. www subdomain. Here’s how
Pageflake’s website’s request looks like with the forms
authentication cookie and Google Analytics cookies:
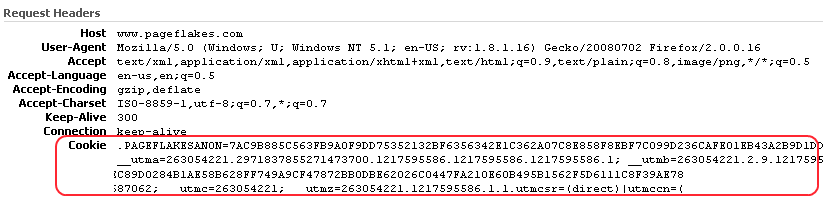
You see a lot of data being sent on the request header which has
no use for any static content. Thus it wastes bandwidth, makes
request reach server slower and produces large IIS logs.
You can solve this problem by loading static contents from
different domain as we have done it at Pageflakes by loading static
contents from a different domain e.g. flakepage.com. As the cookies
are registered only on the www subdomain, browser does not send the
cookies to any other subdomain or domain. Thus requests going to
other domains are smaller and thus faster.
Would not it be great if you could just plugin something in your
ASP.NET project and all the graphics, CSS, javascript URLs
automatically get converted to a different domain URL without you
having to do anything manually like going through all your ASP.NET
pages, webcontrols and manually changing the urls?
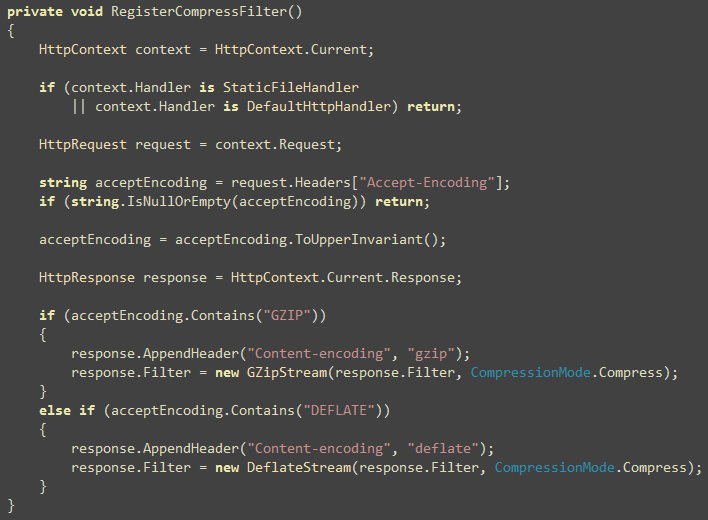
Here’s a nice HttpFilter that will do the exact thing.
You just configure in your web.config what prefix you want
to add in front of your javascript, css and images and the filter
takes care of changing all the links for you when a page is being
rendered.
First you add these keys in your web.config‘s
before the relative URL of your static content. You can define
three different prefix for images, javascripts and css:

So, you can download images from one domain, javascripts from
another domain and css from another domain in order to increase
parallel download. But beware, there’s the overhead of DNS lookup
which is significant. Ideally you should have max three unique
domains used in your entire page, one for the main domain and two
other domain.
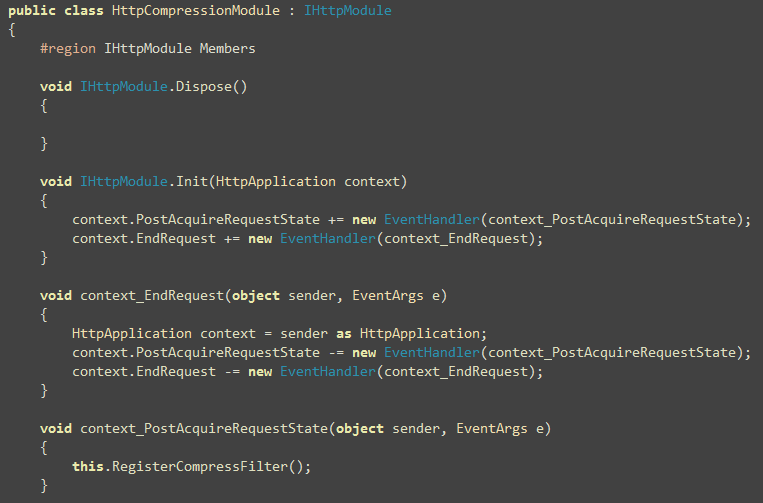
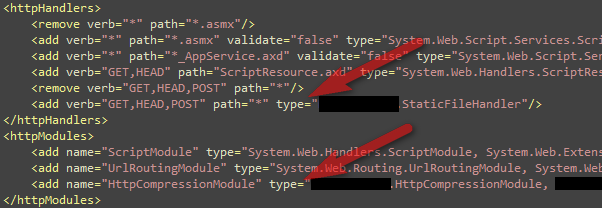
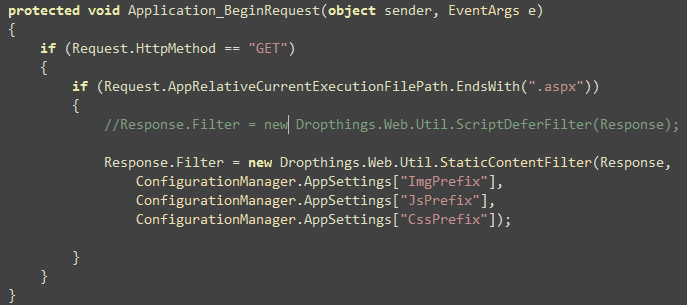
Then you register the Filter on Application_BeginRequest
so that it intercepts all aspx pages:
That’s it! You will see all the tag’s
src attribute, < script> tag’s src
attribute, tag’s href attribute are
automatically prefixed with the prefix defined in
web.config
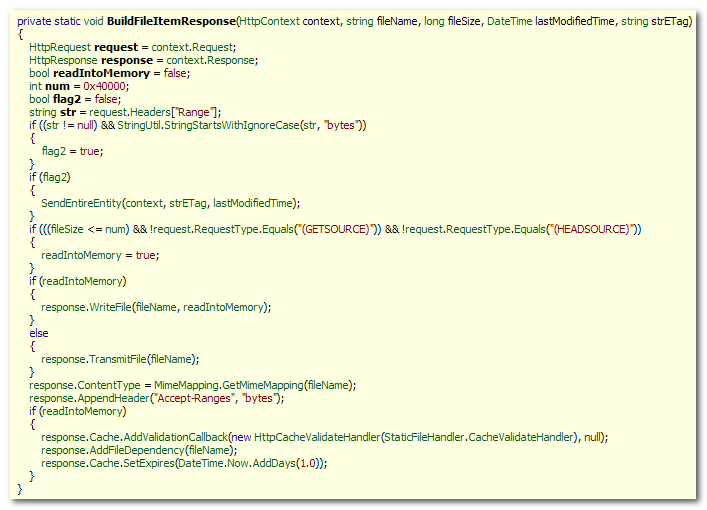
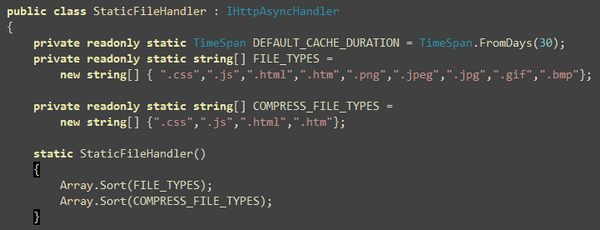
Here’s how the Filter works. First it intercepts the
Write method and then searches through the buffer if there’s
any of the tags. If found, it checks for the src or
href attribute and then sees if the URL is absolute or
relative. If relative, inserts the prefix first and then the
relative value follows.
The principle is relatively simple, but the code is far more
complex than it sounds. As you work with char[] in an
HttpFilter, you need to work with char[] array only,
no string. Moreover, there’s very high performance
requirement for such a filter because it processes each and every
page’s output. So, the filter will be processing megabytes of data
every second on a busy site. Thus it needs to be extremely fast. No
string allocation, no string comparison, no Dictionary or
ArrayList, no StringBuilder or MemoryStream.
You need to forget all these .NET goodies and go back to good old
Computer Science school days and work with arrays, bytes, char and
so on.
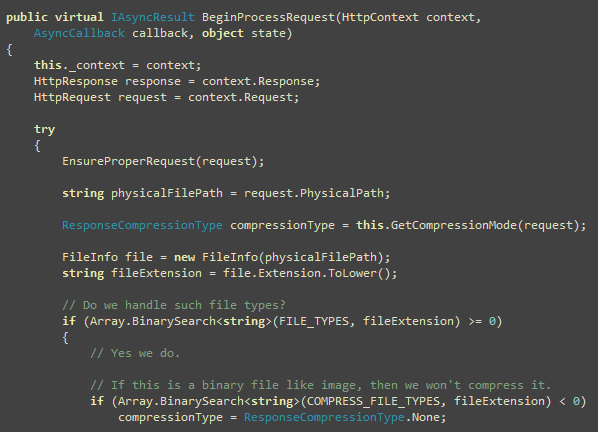
First, we run through the content array provided and see if
there’s any of the intended tag’s start.
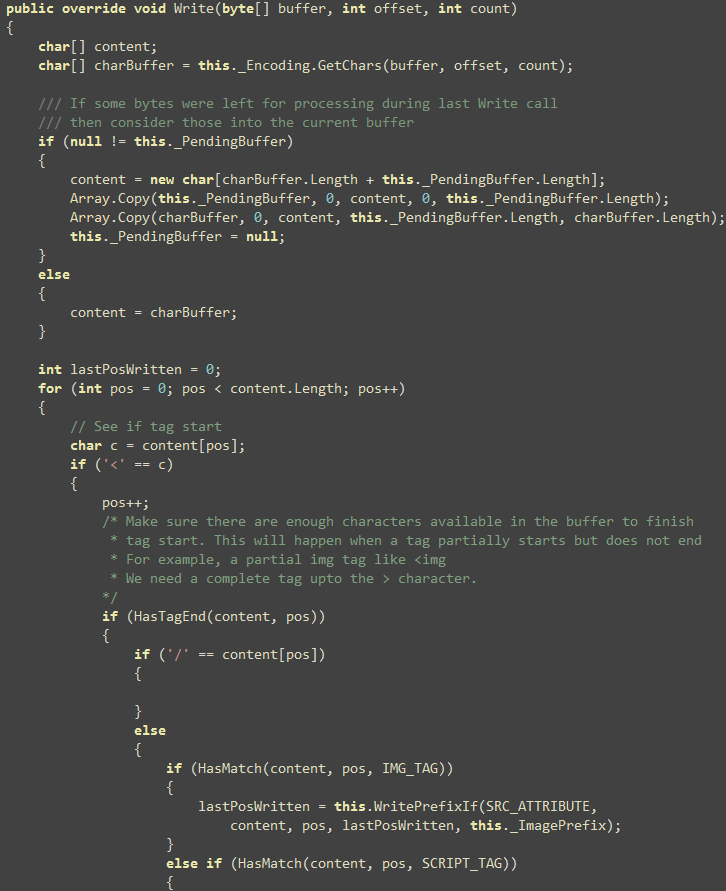
Idea is to find all the image, script and link tags and see what
their src/href value is and inject the prefix if needed. The
WritePrefixIf(…) function does the work of parsing the
attribute. Some cool things to notice here is that, there’s
absolutely no string comparison here. Everything is done on the
char[] passed to the Write method.
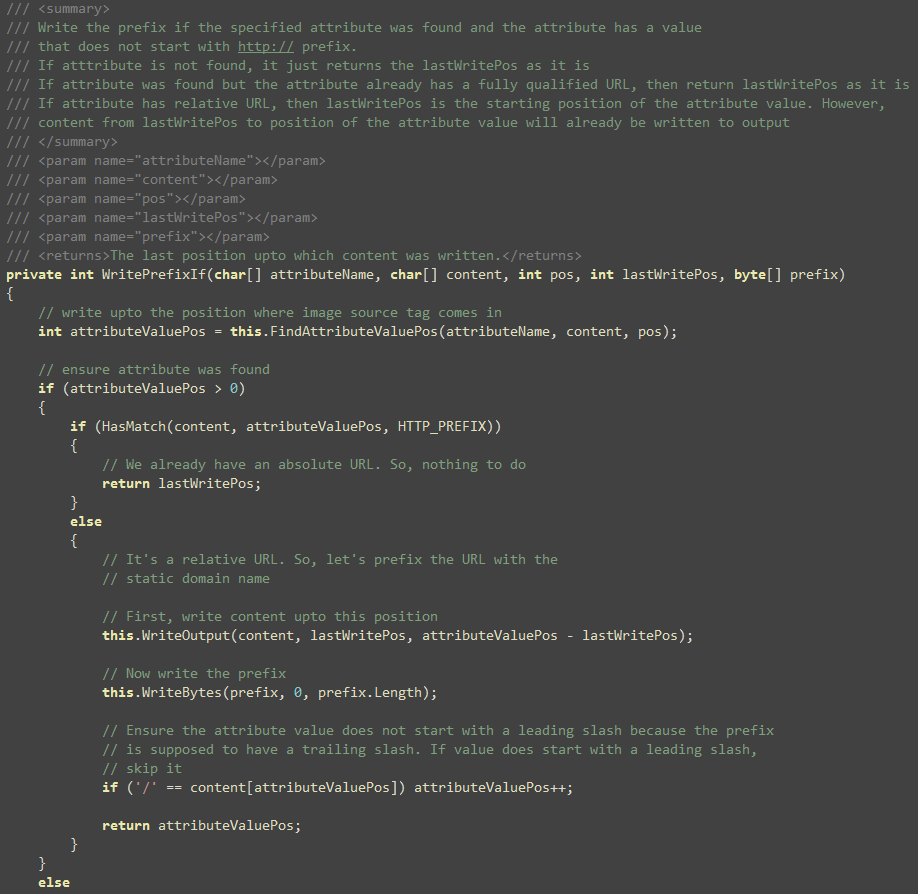
This function checks if src/href attribute is found and
it writes the prefix right after the double quote if the value of
the prefix does not start with http://
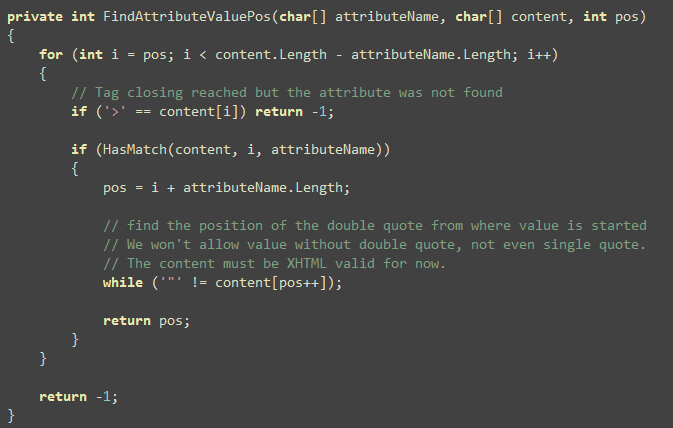
Basically that’s it. The only other interesting thing is the
FindAttributeValuePos. It checks if the specified attribute
exists and if it does, finds the position of the value in the
content array so that content can be flushed up to the value
position.
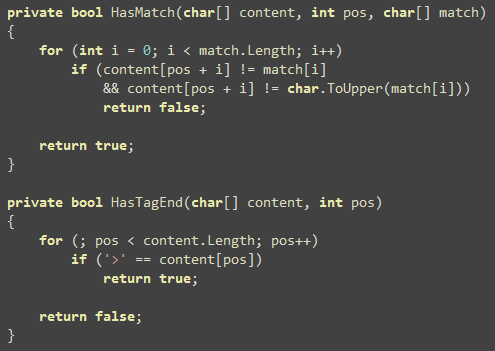
Two other small functions that are worth mentioning are the
compare functions so that you can see, there’s absolutely no string
comparison involved in this entire filter:
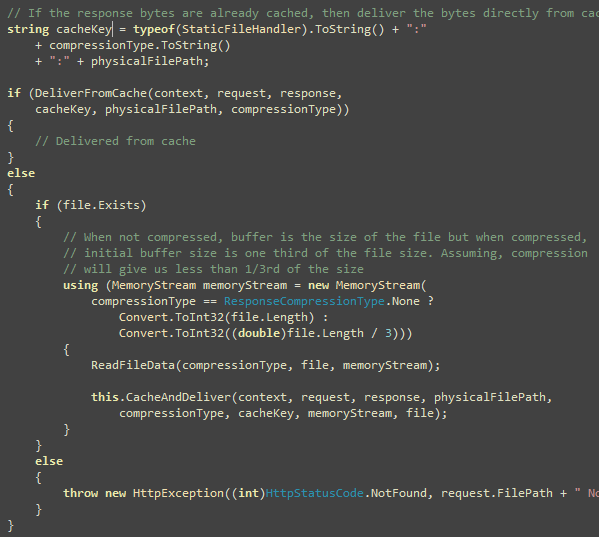
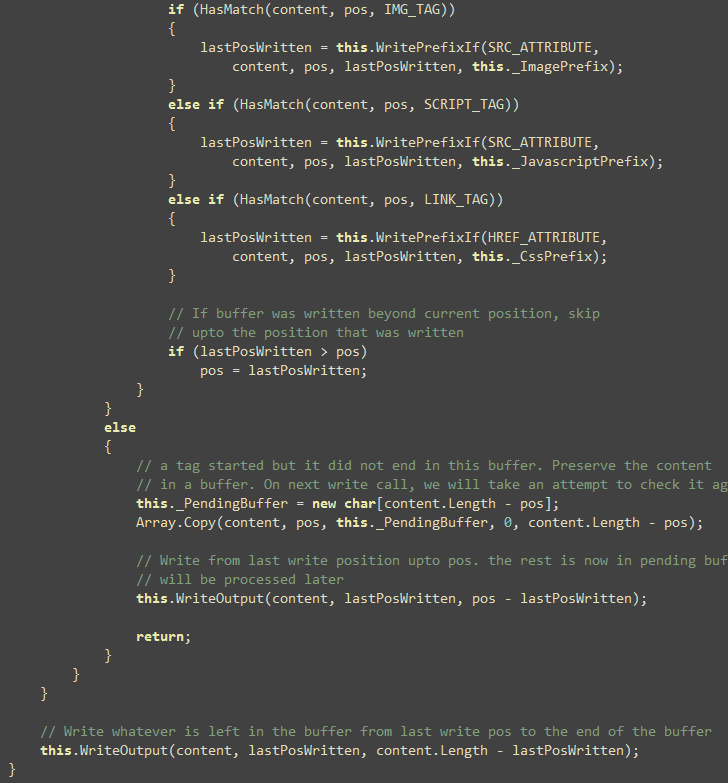
Now the season finally, the remaining code in Write function
that solves several challenges like unfinished tags in a buffer.
It’s possible Write method will pass you a buffer where a tag has
just started, but did not end. Of you can get part of a tag like
handled. Idea is to detect such unfinished tags and store them in a
temporary buffer. When next Write call happens, it will
combine the buffer and process it.
That’s it for the filter’s code.
Download the code
from here. It’s just one class.
You can use this filter in conjunction with the
ScriptDeferFilter that I have showed in CodeProject
article which defers script loading after body and combines
multiple script tags into one for faster download and better
compression and thus significantly faster web page load
performance.
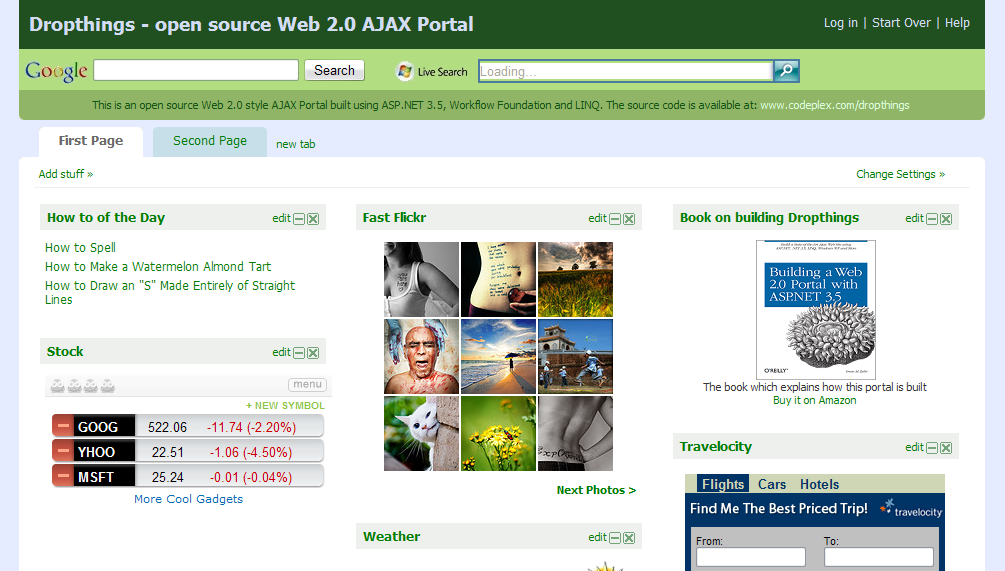
In case you are wondering whether this is production
ready, visit www.dropthings.com and you will see
static content downloads from s.dropthings.com using this
Filter.
| Share this post : |  |
 |
 |
 |
 |
 |
 |
 |
 |