I have two broadband connections. One cheap connection, which I
mostly use for browsing and downloading. Another very expensive
connection that I use for voice chat, remote desktop connection
etc. Now, using these two connections at the same time required two
computers before. But I figured out a way to use both connections
at the same time using the same computer. Here’s how:
Connect the cheap internet connection that is used mostly for
non-critical purpose like downloading, browsing to a wireless
router.
Connect the expensive connection that is used for network
latency sensitive work like Voice Conference, Remote Desktop
directly via LAN.
When you want to establish a critical connection like starting
voice conf app (Skype) or remote desktop client, momentarily
disconnect the wireless. This will make your LAN connection the
only available internet. So, all the new connections will be
established over the LAN. Now you can start Skype and initiate a
voice conference or use Remote Desktop client and connect to a
computer. The connection will be established over LAN.
Now turn on wireless. Wireless will now become the first
preference for Windows to go to internet. So, now you can start
Outlook, browser etc and they will be using the wireless internet
connection. During this time, Skype and Terminal Client is still
connected over the LAN connection. As they use persisted
connection, they keep using the LAN connection and do not switch to
the wireless.
This way you get to use two broadband connections
simultaneously.
Here you see I have data transfer going on through two different
connection. The bottom one is the LAN which is maintaining a
continuous voice data stream. The upper one is the wireless
connection that sometimes consumes bandwidth when I browse.
Using Sysinternal’s TCPView, I can see some connection is going
through LAN and some through Belkin router. The selected ones – the
terminal client and the MSN Messenger is using LAN where the
Internet Explorer and Outlook is working over Wireless
connection.
Every time I create an IIS website, I do some steps, which I
consider as best practice for creating any IIS website for better
performance, maintainability, and scalability. Here’ re the things
I do:
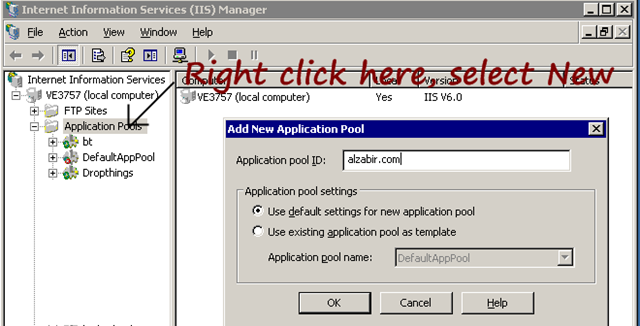
Create a separate application pool for each web
application
I always create separate app pool for each web app because I can
select different schedule for app pool recycle. Some heavy traffic
websites have long recycle schedule where low traffic websites have
short recycle schedule to save memory. Moreover, I can choose
different number of processes served by the app pool. Applications
that are made for web garden mode can benefit from multiple process
where applications that use in-process session, in memory cache
needs to have single process serving the app pool. Hosting all my
application under the DefaultAppPool does not give me the
flexibility to control these per site.
The more app pool you create, the more ASP.NET threads you make
available to your application. Each w3wp.exe has it’s own
thread pool. So, if some application is congesting particular w3wp.exe process, other applications can run happily on
their separate w3wp.exe instance, running under separate app
pool. Each app pool hosts its own w3wp.exe instance.
So, my rule of thumb: Always create new app pool for new web
applications and name the app pool based on the site’s domain name
or some internal name that makes sense. For example, if you are
creating a new website alzabir.com, name the app pool alzabir.com
to easily identify it.
Another best practice: Disable the DefaultAppPool so that
you don’t mistakenly keep adding sites to DefaultAppPool.
First you create a new application pool. Then you create a new
Website or Virtual Directory, go to Properties -> Home Directory
tab -> Select the new app pool.
Customize Website properties for performance,
scalability and maintainability
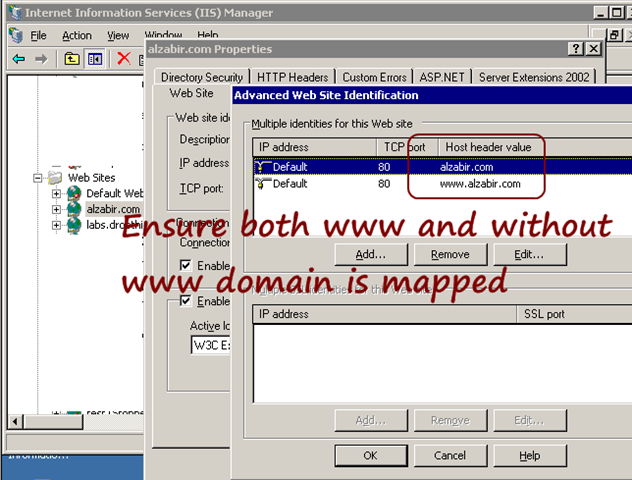
First you map the right host headers to your website. In order
to do this, go to WebSite tab and click on “Advanced” button. Add
mapping for both domain.com and www.domain.com. Most of the time,
people forget to map the domain.com. Thus many visitors skip typing
the www prefix and get no page served.
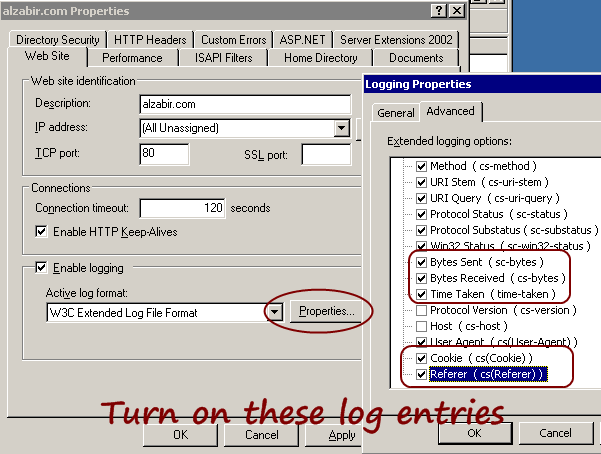
Next turn on some log entries:
These are very handy for analysis. If you want to measure your
bandwidth consumption for specific sites, you need the Bytes Sent.
If you want to measure the execution time of different pages and
find out the slow running pages, you need Time Taken. If you want
to measure unique and returning visitors, you need the Cookie. If
you need to know who is sending you most traffic – search engines
or some websites, you need the Referer. Once these entries are
turned on, you can use variety of Log Analysis tools to do the
analysis. For example, open source AWStats.
But if you are using Google Analytics or something else, you
should have these turned off, especially the Cookie and Referer
because they take quite some space on the log. If you are using
ASP.NET Forms Authentication, the gigantic cookie coming with every
request will produce gigabytes of logs per week if you have a
medium traffic website.
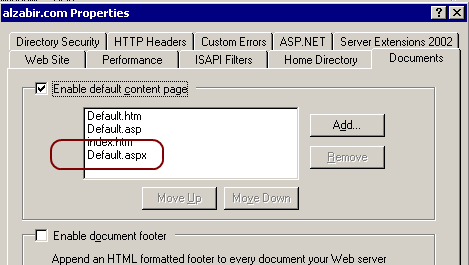
This is kinda no brainer. I add Default.aspx as the default
content page so that, when visitors hit the site without any .aspx
page name, e.g. alzabir.com, they get the default.aspx served.
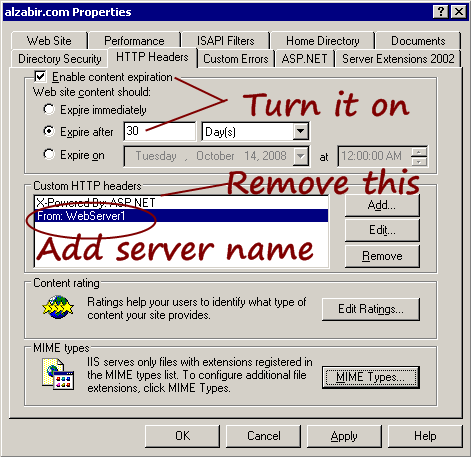
Things I do here:
Turn on Content Expiration. This makes static files remain in
browser cache for 30 days and browser serves the files from its own
cache instead of hitting the server. As a result, when your users
revisit, they don’t download all the static files like images,
javascripts, css files again and again. This one setting
significantly improves your site’s performance.
Remove the X-Powered-By: ASP.NET header. You really
don’t need it unless you want to attach Visual Studio Remote
Debugger to your IIS. Otherwise, it’s just sending 21 bytes on
every response.
Add “From” header and set the server name. I do this on each
webserver and specify different names on each box. It’s handy to
see from which servers requests are being served. When you are
trying to troubleshoot load balancing issues, it comes handy to see
if a particular server is sending requests.
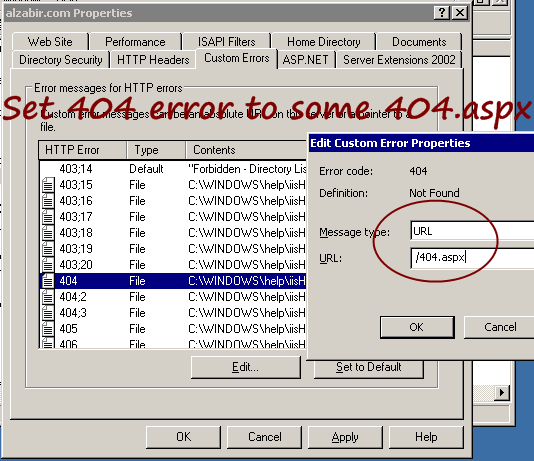
I set the 404 handler to some ASPX so that I can show some
custom error message. There’s a 404.aspx which shows some nice
friendly message and suggests some other pages that user can visit.
However, another reason to use this custom mapping is to serve
extensionless URL from IIS.
Read this blog post for details.
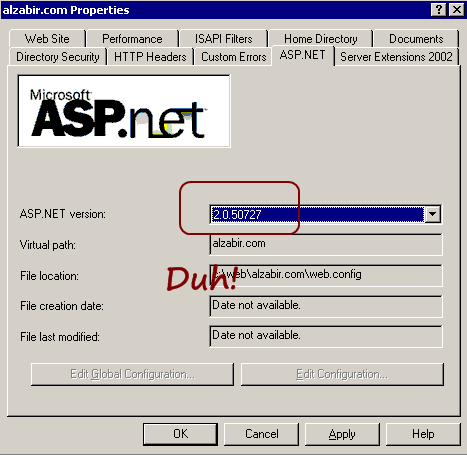
Make sure to set ASP.NET 2.0 for your ASP.NET 2.0, 3.0 and 3.5
websites.
Finally, you must, I repeat you “MUST”
turn on IIS 6.0 gzip compression. This turns on the Volkswagen
V8 engine that is built into IIS to make your site screaming
fast.
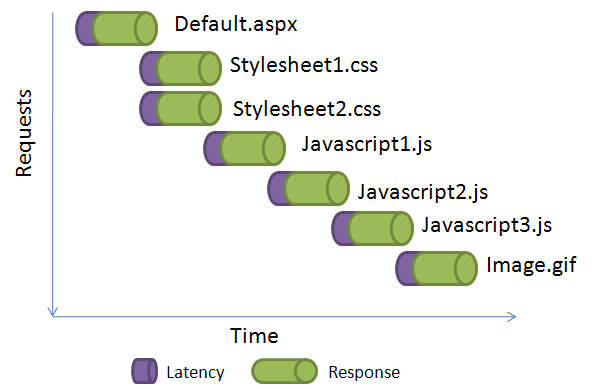
It’s a good practice to use many small Javascript and CSS files
instead of one large Javascript/CSS file for better code
maintainability, but bad in terms of website performance. Although
you should write your Javascript code in small files and break
large CSS files into small chunks but when browser requests those
javascript and css files, it makes one Http request per file. Every
Http Request results in a network roundtrip form your browser to
the server and the delay in reaching the server and coming back to
the browser is called latency. So, if you have four javascripts and
three css files loaded by a page, you are wasting time in seven
network roundtrips. Within USA, latency is average 70ms. So, you
waste 7×70 = 490ms, about half a second of delay. Outside USA,
average latency is around 200ms. So, that means 1400ms of waiting.
Browser cannot show the page properly until Css and Javascripts are
fully loaded. So, the more latency you have, the slower page
loads.
Here’s a graph that shows how each request latency adds up and
introduces significant delay in page loading:
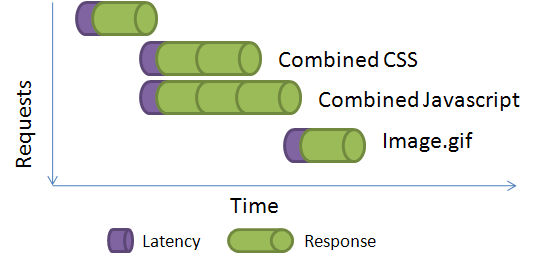
You can reduce the wait time by using a CDN. my previous blog post about using CDN. However, a better
solution is to deliver multiple files over one request using an HttpHandler that combines several files and delivers as one
output. So, instead of putting many < script> or tag, you just put one < script> and one tag, and
point them to the HttpHandler. You tell the handler which
files to combine and it delivers those files in one response. This
saves browser from making many requests and eliminates the
latency.
Here you can see how much improvement you get if you can combine multiple javascripts and css into one.
In a typical web page, you will see many javascripts referenced:
The Http Handler reads the file names defined in a configuration
and combines all those files and delivers as one response. It
delivers the response as gzip compressed to save bandwidth.
Moreover, it generates proper cache header to cache the response in
browser cache, so that, browser does not request it again on future
visits.
You can find details about the HttpHandler from this
CodeProject article:
Generally we put static content (images, css, js) of our website
inside the same web project. Thus they get downloaded from the same
domain like www.dropthings.com. There are three
problems in this approach:
They occupy connections on the same domain www.dropthings.com and thus other
important calls like Web service call do not get a chance to happen
earlier as browser can only make two simultaneous connections per
domain.
If you are using ASP.NET Forms Authentication, then you have
that gigantic Forms Authentication cookie being sent with every
single request on www.dropthings.com. This cookie
gets sent for all images, CSS and JS files, which has no use for
the cookie. Thus it wastes upload bandwidth and makes every request
slower. Upload bandwidth is very limited for users compared to
download bandwidth. Generally users with 1Mbps download speed has
around 128kbps upload speed. So, adding another 100 bytes on the
request for the unnecessary cookie results in delay in sending the
request and thus increases your site load time and the site feels
slow to respond.
It creates enormous IIS Logs as it records the cookies for each
static content request. Moreover, if you are using Google Analytics
to track hits to your site, it issues four big cookies that gets
sent for each and every image, css and js files resulting in slower
requests and even larger IIS log entries.
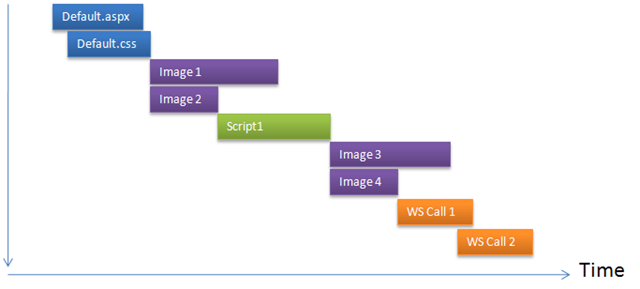
Let’s see the first problem, browser’s two connection limit. See
what happens when content download using two HTTP requests in
parallel:
This figure shows only two files are downloaded in parallel. All
the hits are going to the same domain e.g. www.dropthings.com. As you see,
only two call can execute at the same time. Moreover, due to
browser’s way of handling script tags, once a script is being
downloaded, browser does not download anything else until the
script has downloaded and executed.
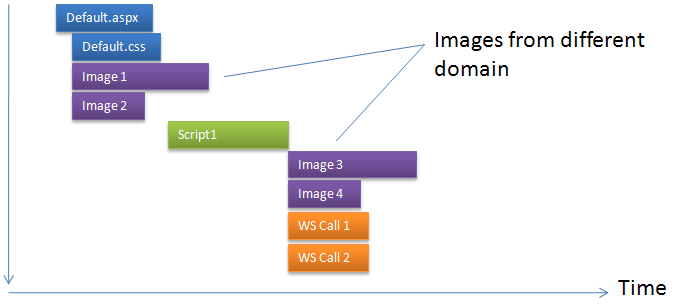
Now, if we can download the images from different domain, which
allows browser to open another two simultaneous connections, then
the page loads a lot faster:
You see, the total page downloads 40% faster. Here only the
images are downloaded from a different domain e.g.
“s.dropthings.com”, thus the calls for the script, CSS and
webservices still go to main domain e.g. www.dropthings.com
The second problem for loading static content from same domain
is the gigantic forms authentication cookie or any other cookie
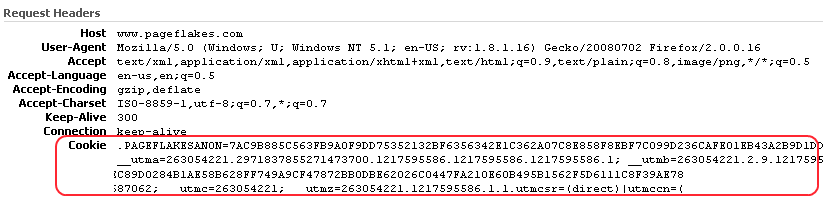
being registered on the main domain e.g. www subdomain. Here’s how
Pageflake’s website’s request looks like with the forms
authentication cookie and Google Analytics cookies:
You see a lot of data being sent on the request header which has
no use for any static content. Thus it wastes bandwidth, makes
request reach server slower and produces large IIS logs.
You can solve this problem by loading static contents from
different domain as we have done it at Pageflakes by loading static
contents from a different domain e.g. flakepage.com. As the cookies
are registered only on the www subdomain, browser does not send the
cookies to any other subdomain or domain. Thus requests going to
other domains are smaller and thus faster.
Would not it be great if you could just plugin something in your
ASP.NET project and all the graphics, CSS, javascript URLs
automatically get converted to a different domain URL without you
having to do anything manually like going through all your ASP.NET
pages, webcontrols and manually changing the urls?
Here’s a nice HttpFilter that will do the exact thing.
You just configure in your web.config what prefix you want
to add in front of your javascript, css and images and the filter
takes care of changing all the links for you when a page is being
rendered.
First you add these keys in your web.config‘s block that defines the prefix to inject
before the relative URL of your static content. You can define
three different prefix for images, javascripts and css:
So, you can download images from one domain, javascripts from
another domain and css from another domain in order to increase
parallel download. But beware, there’s the overhead of DNS lookup
which is significant. Ideally you should have max three unique
domains used in your entire page, one for the main domain and two
other domain.
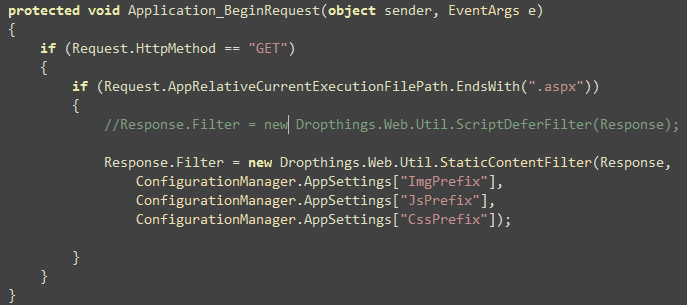
Then you register the Filter on Application_BeginRequest
so that it intercepts all aspx pages:
That’s it! You will see all the tag’s src attribute, < script> tag’s src
attribute, tag’s href attribute are
automatically prefixed with the prefix defined in web.config
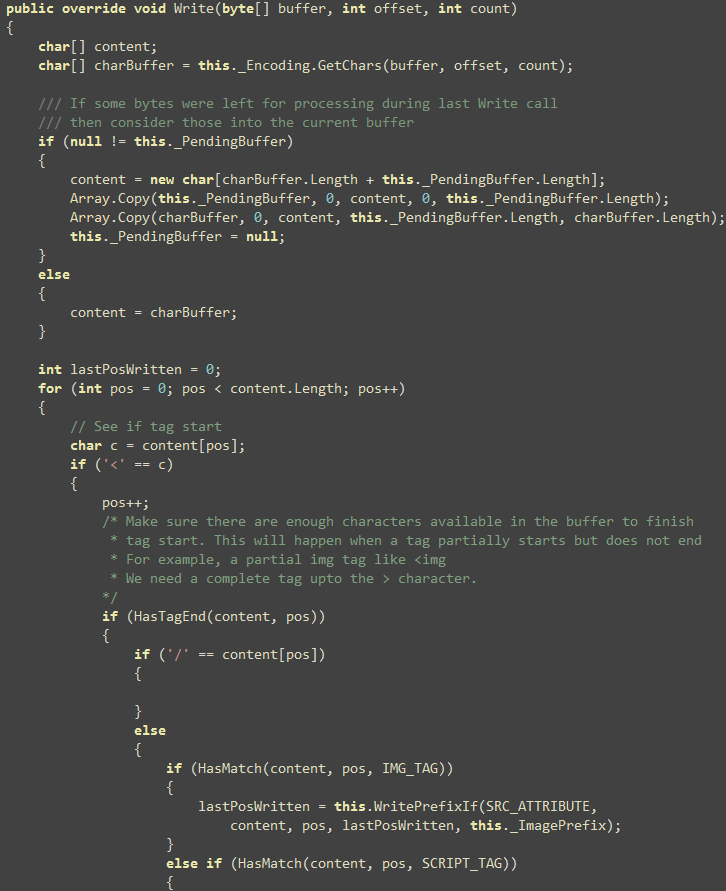
Here’s how the Filter works. First it intercepts the Write method and then searches through the buffer if there’s
any of the tags. If found, it checks for the src or href attribute and then sees if the URL is absolute or
relative. If relative, inserts the prefix first and then the
relative value follows.
The principle is relatively simple, but the code is far more
complex than it sounds. As you work with char[] in an HttpFilter, you need to work with char[] array only,
no string. Moreover, there’s very high performance
requirement for such a filter because it processes each and every
page’s output. So, the filter will be processing megabytes of data
every second on a busy site. Thus it needs to be extremely fast. No
string allocation, no string comparison, no Dictionary or ArrayList, no StringBuilder or MemoryStream.
You need to forget all these .NET goodies and go back to good old
Computer Science school days and work with arrays, bytes, char and
so on.
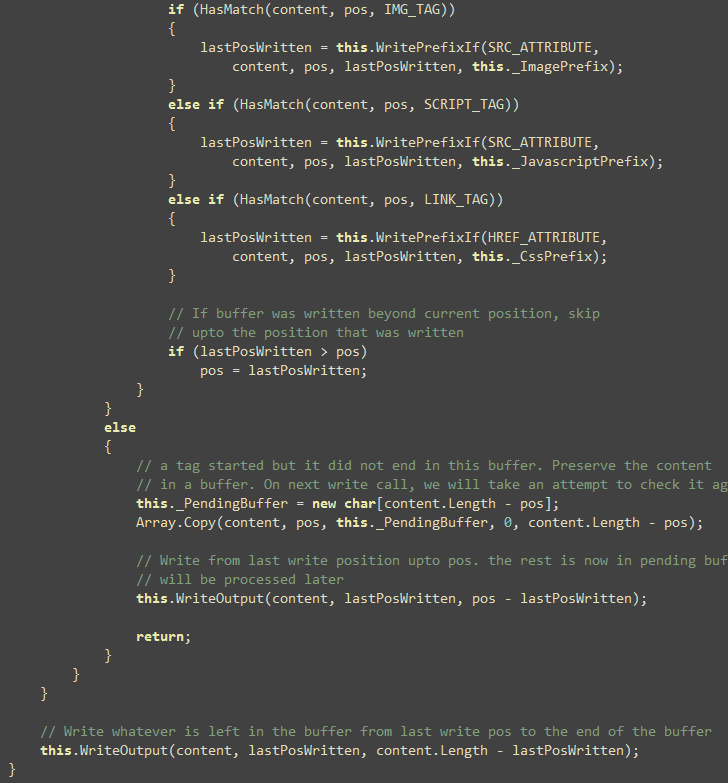
First, we run through the content array provided and see if
there’s any of the intended tag’s start.
Idea is to find all the image, script and link tags and see what
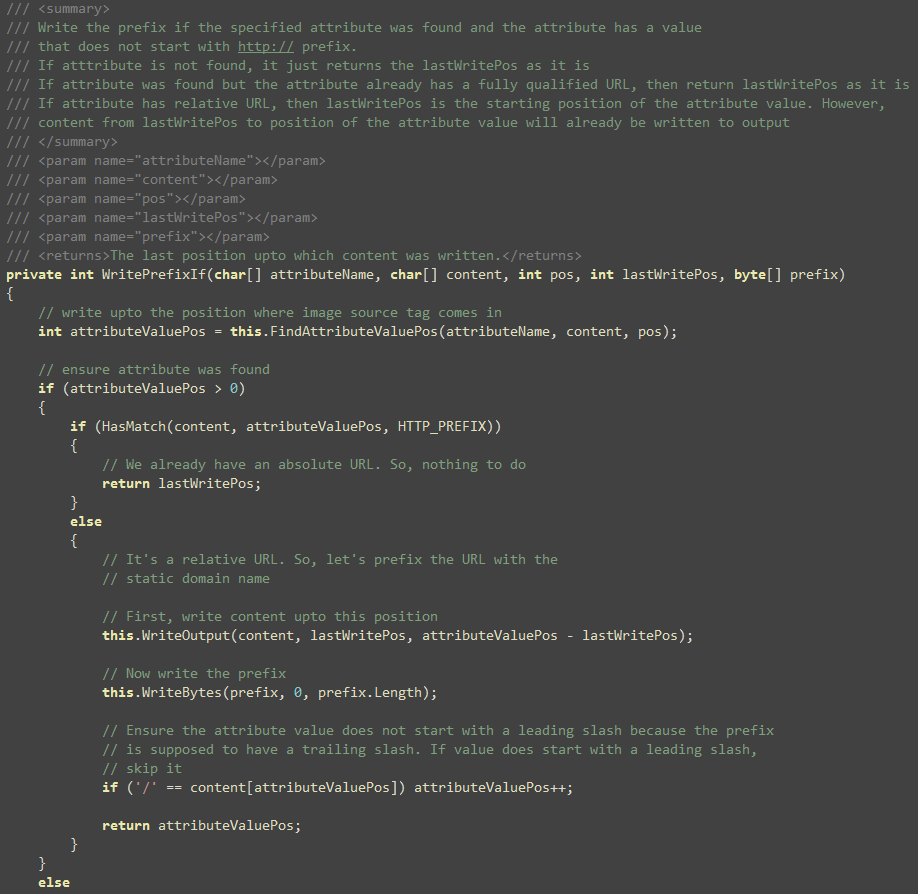
their src/href value is and inject the prefix if needed. The WritePrefixIf(…) function does the work of parsing the
attribute. Some cool things to notice here is that, there’s
absolutely no string comparison here. Everything is done on the char[] passed to the Write method.
This function checks if src/href attribute is found and
it writes the prefix right after the double quote if the value of
the prefix does not start with http://
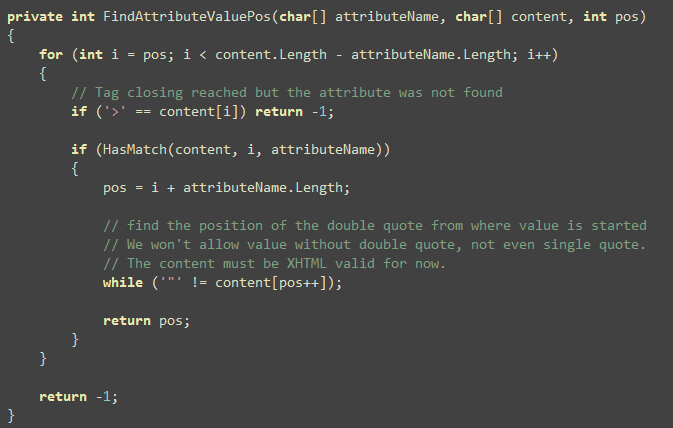
Basically that’s it. The only other interesting thing is the FindAttributeValuePos. It checks if the specified attribute
exists and if it does, finds the position of the value in the
content array so that content can be flushed up to the value
position.
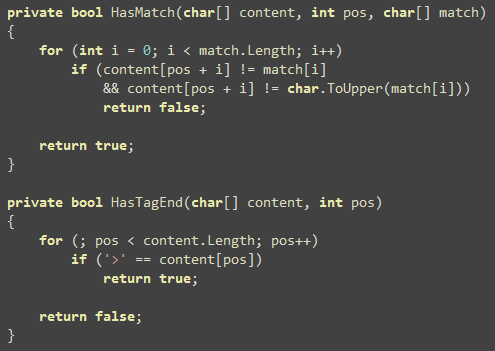
Two other small functions that are worth mentioning are the
compare functions so that you can see, there’s absolutely no string
comparison involved in this entire filter:
Now the season finally, the remaining code in Write function
that solves several challenges like unfinished tags in a buffer.
It’s possible Write method will pass you a buffer where a tag has
just started, but did not end. Of you can get part of a tag like and that’s it. So, these scenario needs to be
handled. Idea is to detect such unfinished tags and store them in a
temporary buffer. When next Write call happens, it will
combine the buffer and process it.
In case you are wondering whether this is production
ready, visit www.dropthings.com and you will see
static content downloads from s.dropthings.com using this
Filter.
There are several problems with ASP.NET MVC application when
deployed on IIS 6.0:
Extensionless URLs give 404 unless some URL Rewrite module is
used or wildcard mapping is enabled
IIS 6.0 built-in compression does not work for dynamic
requests. As a result, ASP.NET pages are served uncompressed
resulting in poor site load speed.
Mapping wildcard extension to ASP.NET introduces the following
problems:
Slow performance as all static files get handled by ASP.NET and
ASP.NET reads the file from file system on every call
Expires headers doesn’t work for static content as IIS does not
serve them anymore. Learn about benefits of expires header from
here. ASP.NET serves a fixed expires header that makes content
expire in a day.
Cache-Control header does not produce max-age properly and thus
caching does not work as expected. Learn about caching best
practices from
here.
After deploying on a domain as the root site, the homepage
produces HTTP 404.
Problem 1: Visiting your website’s homepage gives 404 when
hosted on a domain
You have done the wildcard mapping, mapped .mvc extention to
ASP.NET ISAPI handler, written the route mapping for Default.aspx
or default.aspx (lowercase), but still when you visit your homepage
after deployment, you get:
You will find people banging their heads on the wall here:
Solution is to capture hits going to “/” and then rewrite it to
Default.aspx:
You can apply this approach to any URL that ASP.NET MVC is not
handling for you and it should handle. Just see the URL reported on
the 404 error page and then rewrite it to a proper URL.
Problem 2: IIS 6 compression is no longer working after
wildcard mapping
When you enable wildcard mapping, IIS 6 compression no longer
works for extensionless URL because IIS 6 does not see any
extension which is defined in IIS Metabase. You can learn about IIS
6 compression feature and how to configure it properly from
my earlier post.
Solution is to use an HttpModule to do the compression for
dynamic requests.
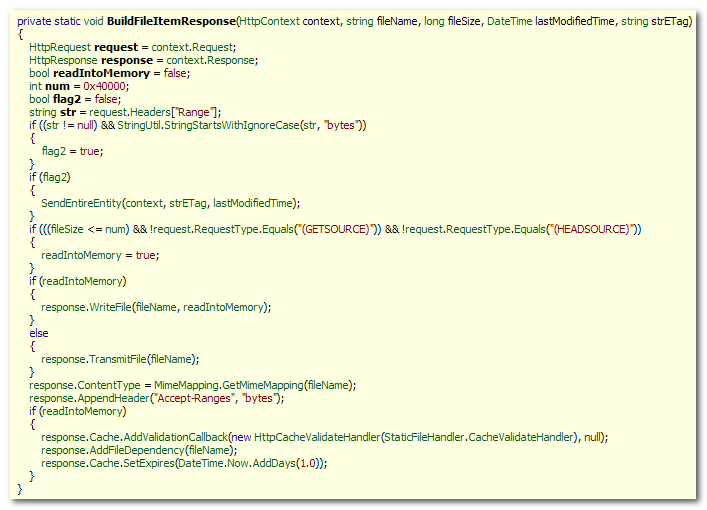
Problem 3: ASP.NET ISAPI does not cache Static Files
When ASP.NET’s DefaultHttpHandler serves static files, it
does not cache the files in-memory or in ASP.NET cache. As a
result, every hit to static file results in a File read. Below is
the decompiled code in DefaultHttpHandler when it handles a
static file. As you see here, it makes a file read on every hit and
it only set the expiration to one day in future. Moreover, it
generates ETag for each file based on file’s modified date.
For best caching efficiency, we need to get rid of that ETag, produce an expiry date on far future (like 30 days),
and produce Cache-Control header which offers better control
over caching.
So, we need to write a custom static file handler that will
cache small files like images, Javascripts, CSS, HTML and so on in
ASP.NET cache and serve the files directly from cache instead of
hitting the disk. Here are the steps:
Install an HttpModule that installs a Compression Stream
on Response.Filter so that anything written on Response gets
compressed. This serves dynamic requests.
Replace ASP.NET’s DefaultHttpHandler that listens on *.*
for static files.
Write our own Http Handler that will deliver compressed
response for static resources like Javascript, CSS, and HTML.
Here’s the mapping in ASP.NET’s web.config for the DefaultHttpHandler. You will have to replace this with your
own handler in order to serve static files compressed and
cached.
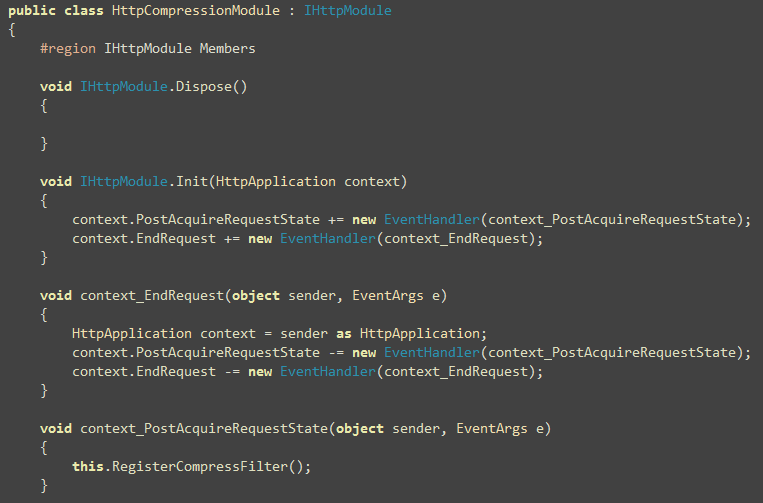
Solution 1: An Http Module to compress dynamic requests
First, you need to serve compressed responses that are served by
the MvcHandler or ASP.NET’s default Page Handler. The
following HttpCompressionModule hooks on the Response.Filter and installs a GZipStream or DeflateStream on it so that whatever is written on the
Response stream, it gets compressed.
These are formalities for a regular HttpModule. The real
hook is installed as below:
Here you see we ignore requests that are handled by ASP.NET’s DefaultHttpHandler and our own StaticFileHandler that
you will see in next section. After that, it checks whether the
request allows content to be compressed. Accept-Encoding
header contains “gzip” or “deflate” or both when browser supports
compressed content. So, when browser supports compressed content, a
Response Filter is installed to compress the output.
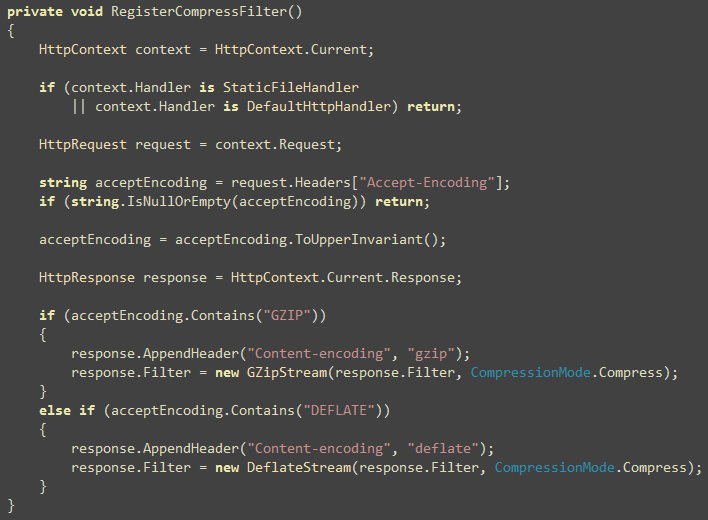
Solution 2: An Http Module to compress and cache static file
requests
Here’s how the handler works:
Hooks on *.* so that all unhandled requests get served by the
handler
Handles some specific files like js, css, html, graphics files.
Anything else, it lets ASP.NET transmit it
The extensions it handles itself, it caches the file content so
that subsequent requests are served from cache
It allows compression of some specific extensions like js, css,
html. It does not compress graphics files or any other
extension.
Let’s start with the handler code:
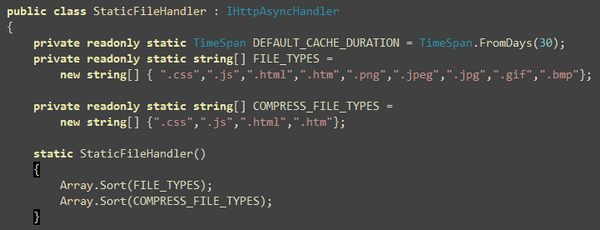
Here you will find the extensions the handler handles and the
extensions it compresses. You should only put files that are text
files in the COMPRESS_FILE_TYPES.
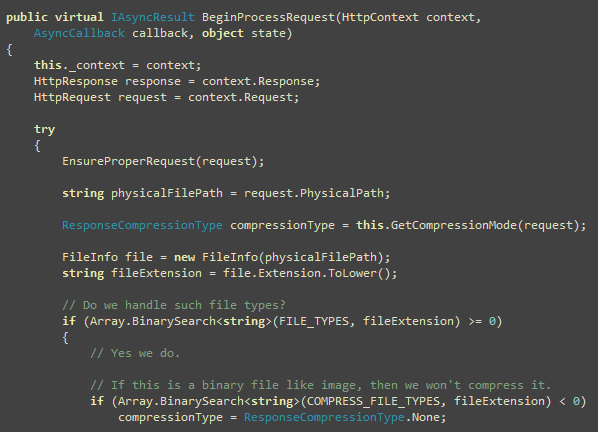
Now start handling each request from BeginProcessRequest.
Here you decide the compression mode based on Accept-Encoding header. If browser does not support
compression, do not perform any compression. Then check if the file
being requested falls in one of the extensions that we support. If
not, let ASP.NET handle it. You will see soon how.
Calculate the cache key based on the compression mode and the
physical path of the file. This ensures that no matter what the URL
requested, we have one cache entry for one physical file. Physical
file path won’t be different for the same file. Compression mode is
used in the cache key because we need to store different copy of
the file’s content in ASP.NET cache based on Compression Mode. So,
there will be one uncompressed version, a gzip compressed version
and a deflate compressed version.
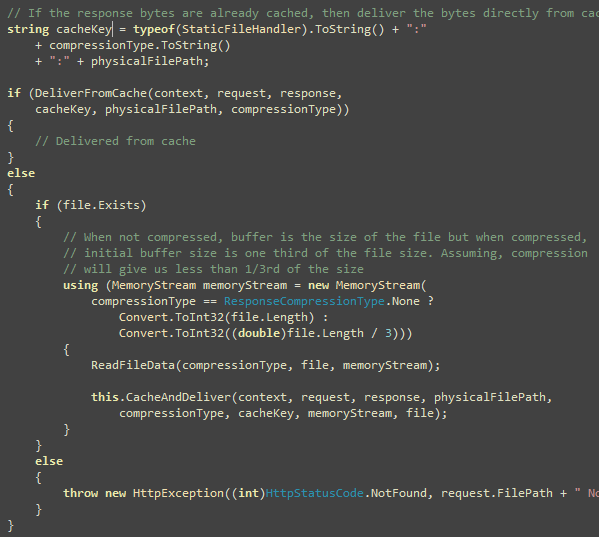
Next check if the file exits. If not, throw HTTP 404. Then
create a memory stream that will hold the bytes for the file or the
compressed content. Then read the file and write in the memory
stream either directly or via a GZip or Deflate stream. Then cache
the bytes in the memory stream and deliver to response. You will
see the ReadFileData and CacheAndDeliver functions
soon.
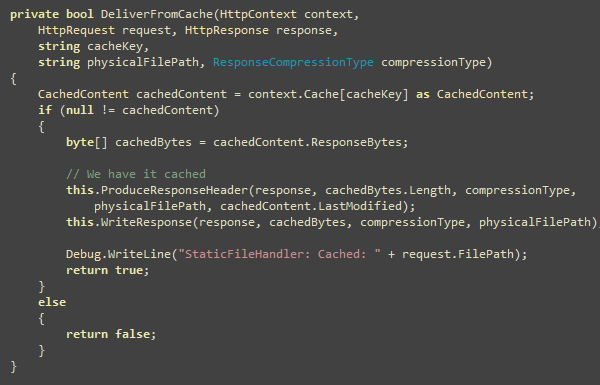
This function delivers content directly from ASP.NET cache. The
code is simple, read from cache and write to the response.
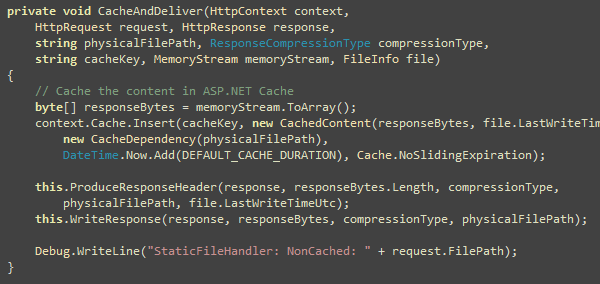
When the content is not available in cache, read the file bytes
and store in a memory stream either as it is or compressed based on
what compression mode you decided before:
Here bytes are read in chunk in order to avoid large amount of
memory allocation. You could read the whole file in one shot and
store in a byte array same as the size of the file length. But I
wanted to save memory allocation. Do a performance test to figure
out if reading in 8K chunk is not the best approach for you.
Now you have the bytes to write to the response. Next step is to
cache it and then deliver it.
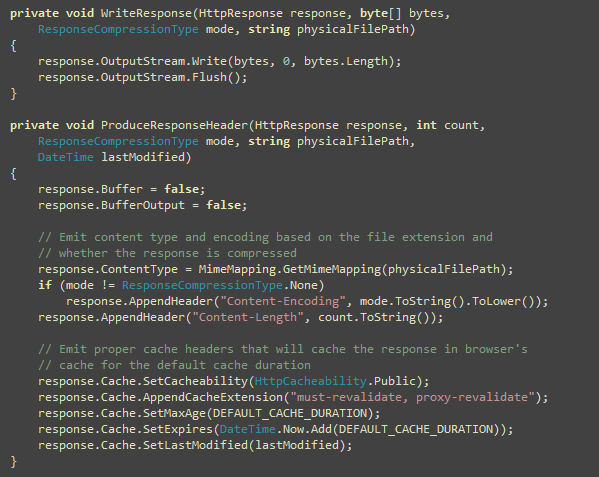
Now the two functions that you have seen several times and have
been wondering what they do. Here they are:
WriteResponse has no tricks, but ProduceResponseHeader has much wisdom in it. First it turns
off response buffering so that ASP.NET does not store the written
bytes in any internal buffer. This saves some memory allocation.
Then it produces proper cache headers to cache the file in browser
and proxy for 30 days, ensures proxy revalidate the file after the
expiry date and also produces the Last-Modified date from
the file’s last write time in UTC.
How to use it
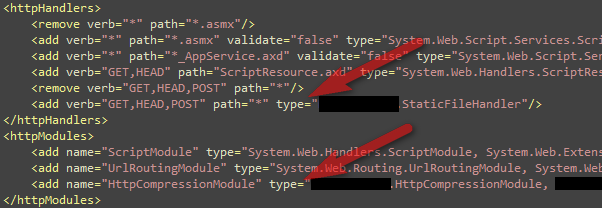
Get the HttpCompressionModule and StaticFileHandler from:
Then install them in web.config. First you install the StaticFileHandler by removing the existing mapping for
path=”*” and then you install the HttpCompressionModule.
That’s it! Enjoy a faster and more responsive ASP.NET MVC
website deployed on IIS 6.0.
ensure allows you to load Javascript, HTML and CSS
on-demand, whenever they are needed. It saves you from writing a
gigantic Javascript framework up front so that you can ensure all
functions are available whenever they are needed. It also saves you
from delivering all possible html on your default page (e.g.
default.aspx) hoping that they might some day be needed on some
user action. Delivering Javascript, html fragments, CSS during
initial loading that is not immediately used on first view makes
initial loading slow. Moreover, browser operations get slower as
there are lots of stuff on the browser DOM to deal with. So, ensure saves you from delivering unnecessary
javascript, html and CSS up front, instead load them on-demand.
Javascripts, html and CSS loaded by ensure remain in
the browser and next time when ensure is called with
the same Javascript, CSS or HTML, it does not reload them and thus
saves from repeated downloads.
Ensure supports jQuery, Microsoft ASP.NET AJAX and Prototype framework. This
means you can use it on any html, ASP.NET, PHP, JSP page that uses
any of the above framework.
For example, you can use ensure to download
Javascript on demand:
ensure( { js: "Some.js" }, function() { SomeJS(); // The function SomeJS is available in Some.js only });
The above code ensures Some.js is available before executing the
code. If the SomeJS.js has already been loaded, it executes the
function write away. Otherwise it downloads Some.js, waits until it
is properly loaded and only then it executes the function. Thus it
saves you from deliverying Some.js upfront when you only need it
upon some user action.
Similarly you can wait for some HTML fragment to be available,
say a popup dialog box. There’s no need for you to deliver HTML for
all possible popup boxes that you will ever show to user on your
default web page. You can fetch the HTML whenever you need
them.
ensure( {html: "Popup.html"}, function() { // The element "Popup" is available only in Popup.html document.getElementById("Popup").style.display = ""; });
The above code downloads the html from “Popup.html” and adds it
into the body of the document and then fires the function. So, you
code can safely use the UI element from that html.
You can mix match Javascript, html and CSS altogether in one ensure call. For example,
You might think you are going to end up writing a lot of ensure code all over your Javascript code and result
in a larger Javascript file than before. In order to save you
javascript size, you can define shorthands for commonly used
files:
While loading html, you can specify a container element where
ensure can inject the loaded HTML. For example, you can say load
HtmlSnippet.html and then inject the content inside a DIV named
“exampleDiv”
A web page can load a lot faster and feel faster if the
javascripts on the page can be loaded after the visible content has
been loaded and multiple javascripts can be batched into one
download. Browsers download one external script at a time and
sometimes pause rendering while a script is being downloaded and
executed. This makes web pages load and render slow when there are
multiple javascripts on the page. For every javascript reference,
browser stops downloading and processing of any other content on
the page and some browsers (like IE6) pause rendering while it
processes the javascript. This gives a slow loading experience and
the web page kind of gets ‘stuck’ frequently. As a result, a web
page can only load fast when there are small number of external
scripts on the page and the scripts are loaded after the visible
content of the page has loaded.
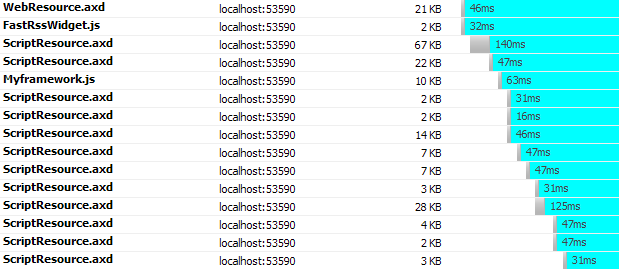
Here’s an example, when you visit
http://dropthings.omaralzabir.com, you see a lot of Javascripts
downloading. Majority of these are from the ASP.NET AJAX framework
and the ASP.NET AJAX Control Toolkit project.
Figure: Many scripts downloaded on a typical ASP.NET AJAX page
having ASP.NET AJAX Control Toolkit
As you see, browser gets stuck for 15 times as it downloads and
processes external scripts. This makes page loading “feel” slower.
The actual loading time is also pretty bad because these 15 http
requests waste 15*100ms = 1500ms on the network latency inside USA.
Outside USA, the latency is even higher. Asia gets about 270ms and
Australia gets about 380ms latency from any server in USA. So,
users outside USA wastes 4 to 6 seconds on network latency where no
data is being downloaded. This is an unacceptable performance for
any website.
You pay for such high number of script downloads only because
you use two extenders from AJAX Control Toolkit and the UpdatePanel of
ASP.NET AJAX.
If we can batch the multiple individual script calls into one
call like Scripts.ashx as shown in the
picture below and download several scripts together in one shot
using an HTTP Handler, it saves us a lot of http connection which
could be spent doing other valuable work like downloading CSS for
the page to show content properly or downloading images on the page
that is visible to user.
Figure: Download several javascripts over one connection and save
call and latency
The Scripts.ashx
handler can not only download multiple scripts in one shot, but
also has a very short URL form. For example:
/scripts.ashx?initial=a,b,c,d,e&/
Compared to conventional ASP.NET ScriptResource URLs like:
The benefits of downloading multiple Javascript over one http
call are:
Saves expensive network roundtrip latency where neither browser
nor the origin server is doing anything, not even a single byte is
being transmitted during the latency
Create less “pause” moments for the browser. So, browser can
fluently render the content of the page and thus give user a fast
loading feel
Give browser move time and free http connections to download
visible artifacts of the page and thus give user a “something’s
happening” feel
When IIS compression is enabled, the total size of individually
compressed files is greater than multiple files compressed after
they are combined. This is because each compressed byte stream has
compression header in order to decompress the content.
This reduces the size of the page html as there are only a few
handful of script tag. So, you can easily saves hundreds of bytes
from the page html. Especially when ASP.NET AJAX produces gigantic WebResource.axd and ScriptResource.axd
URLs that have very large query parameter
The solution is to dynamically parse the response of a page
before it is sent to the browser and find out what script
references are being sent to the browser. I have built an http
module which can parse the generated html of a page and find out
what are the script blocks being sent. It then parses those script
blocks and find the scripts that can be combined. Then it takes out
those individual script tags from the response and adds one script
tag that generates the combined response of multiple script
tags.
For example, the homepage of Dropthings.com produces the
following script tags: