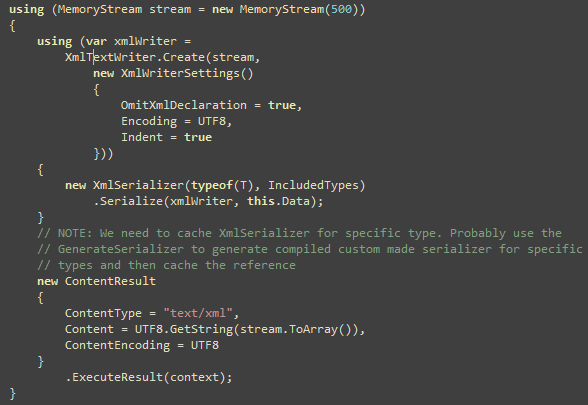
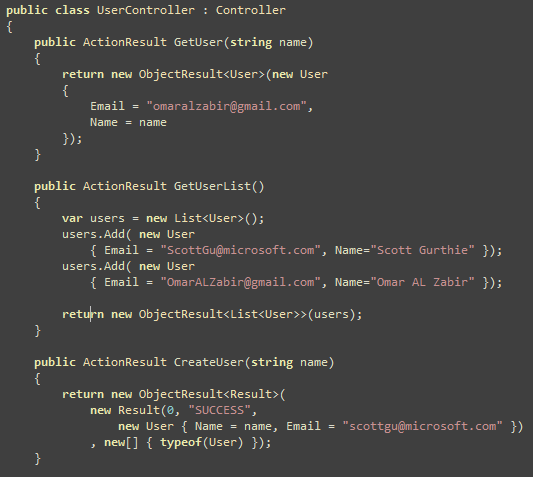
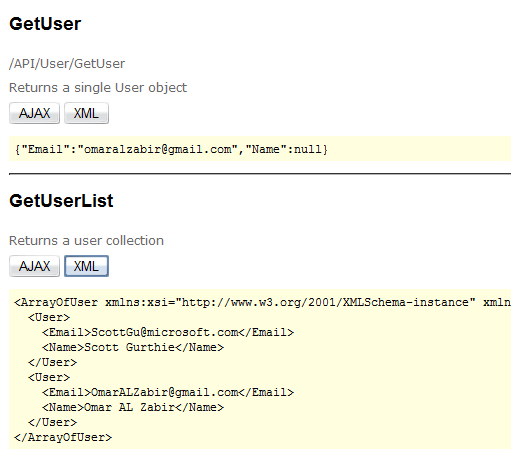
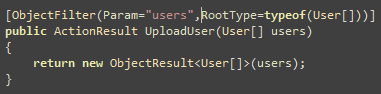
One of my friends, who runs his own offshore development shop,
was having nightmare situation with one of his customers. He’s way
overdue on a release, the customer is screaming everyday, he’s
paying his team from his own pocket, customer is sending an ever
increasing list of changes and so on. Here’s how we discussed some
ideas to get out of such a situation and make sure it does not
repeat in future:
Kabir: Hey, can you help me? My customer is making us
work for free for extra two months to fix bugs from our last
delivery. We did what he said. But after he saw the output, he came
up with hundred changes, which he somehow presents as bugs or
missing features and make them look like they are all our fault and
making us work for last two months for free. He is sending new
changes every week. We have no idea when we will complete the
iteration.
Omar: I see. Did you get a signed list of requirements
from customer before you started the development?
Kabir: Of course, I did. He sent us a word document
explaining what he wants and we sent him a task breakup with hour
estimates and total duration of three months. Now after three
months when we showed him the product, he said, it’s no where close
to what he had expected. Then he sent a gigantic list of things to
change.
Omar: All of those are bugs?
Kabir: Of course not. Most of them are new features.
Omar: Then why don’t you say those are new features? You have
the original word document to prove. Just ask him to show where in
the word document did he said X needs to be done?
Kabir: Well…, he’s tricky. He somehow makes things look
like it is obvious that X needs to be done and he’s not going to
accept a requirement as done until X is done. For example, he said
there must be a complete login form in the homepage. So, we did a
typical login form with user name, password and OK, Cancel button.
Now he says where’s the email verification thing? We said, you did
not ask for it. He said, “this is obvious, every login form has a
forgot password and email verification; I said *complete* login
form, not half-baked login form”. So, you see, we can’t really
argue to keep our image. Then, we did the login form exactly how he
said. Now he says, where the client side validations of proper
email address, username length, password confirmation? We said, you
never asked for it! He says, “come on, every single website
nowadays has AJAX enabled client side validation, do I have to tell
you every single thing? Aren’t you guys smart enough to figure this
out? You are already doing this for the third time, can’t you do it
really well this time?”
Omar: OK, stop. I see what’s your problem. Some customer
will always try to make you work more for less money. They will try
to squeeze out every bit of development they can for their bucks.
So, you have to be extra careful on how much you commit to them and
make sure they cannot chip in more requirements while development
is going on or when you deliver a version. Mockups are one good way
to make sure things are crystal clear between you and
customer. Did you not show him mockups of the features that
you will be building and make him sign those mockups?
Kabir: Yes, I made some mockups. But they were simple
mockups. I did not show the validations or all those side jobs like
sending verification emails.
Omar: Did you run those mockups through your engineers?
They could have told you about those details.
Kabir: No, I did not because developers don’t work on the
project until I get a signoff from client. So, I prepare all the
mockups myself to save cost.
Omar: So, this is the first problem. The mockups were as
ambiguous as the customer’s word document. Basically the mockups
just reflected the sentences in word document. Mockups did not
really show all possible navigations (ok, cancel, forgot, signup),
system messages, system actions behind the scene, workflows etc.
Are you getting what I am saying?
Kabir: Yes. Come on, I am not a developer. I can’t think
of every single details. That’s what developers do when they start
working on it.
Omar: But you provide estimates based on your mockups
right? So, if mockup shows there’s only a simple login form and
change password link, you charge 5 hours for it. But then when you
realize you have to send email for change password, email needs to
contain a tokenized URL, that URL needs to show a change password
form, where you need to validate using CAPTCHA etc, it becomes 20
hours of work. Right?
Kabir: Well yes. Generally I multiply all estimates by
1.5 just to be safe. But things have gone 3X to 10X off original
estimate.
Omar: Yes, I just gave you an example how a login form
estimate can go 4X off when the mockup is not run through an
engineer and the important issues are not addressed.
Kabir: So, you are saying I have to prepare all mockup
with an engineer?
Omar: In general, yes, since you aren’t good enough to
figure those out yourself; no offence. You will get good enough
after you build couple of products and get your a** kicked couple
of times, like mine. Mine got kicked about 17 times. After that it
became so hard that when I sit on it, I produce really good
mockups. After some more kicks, I hope to get 100% perfect in my
mockups.
Kabir: Ok, so the process is, I get word doc from
customer. I produce mockups from it. Then I run them through
engineers to add more details to them. Then after review with
customer, I run them through engineers again to estimate. Then I
ask customer to sign-off on the mockups and the estimate,
correct?
Omar: Well, first let me say, you don’t do a three month
long iteration since you are far away from your customer. You do
short two weeks sprints. Do you know SCRUM?
Kabir: Yes, one of our team does it.
Omar: I assume the team that got their a** kicked don’t
do it?
Kabir: right, they don’t.
Omar: OK, then first you start doing SCRUM. I won’t teach
you details. You can study about SCRUM online. Now, you collect
‘user stories’ from customer. If customer does not give you user
stories, just vague paras of requirements, you break the
requirements into small user stories. Understood?
Kabir: No, give example.
Omar: OK, say customer wants a *complete* login form. You
break it into couple of stories like:
- User clicks on “login” link from homepage so that user can
login to the system
- User enters username (min 5, max 255 chars, only alphanumeric)
in the username text field
- User enters password (min 5, max 50 chars, only alphanumeric)
in the password field
- User clicks on “OK” button after entering username and
password.
- System validates username and password and shows the secure
portal if credential is valid and user has permission to login and
account is not locked.
Understood what user stories are?
Kabir: Yes, but you are missing all the validations that
we also overlooked and now we are working two months for free. This
“user stories” do not help at all.
Omar: Hold on, you just saw basic steps of a user story.
Now you describe each user story with the following:
- All possible inputs of user and their valid format
- All possible system generated messages for invalid input
- All possible alternate navigation from the main user story. For
example, while entering password, user can click on a help icon so
that user can see what kind of passwords are allowed.
Got it?
Kabir: Now it’s starting to make sense. Then what? Show
these user stories to customers?
Omar: No, show them to your lead engineer who has enough
experience to identify if you missed something. Your Engr should
point out all the alternative system actions at least.
Kabir: What if my Engr can’t figure them out? What if
he’s just as dumb as me?
Omar: Fire him. Get a pay cut for yourself.
Kabir: Seriously, what do I do if that’s the case?
Omar: Your engineers will *always* come up with issues
with your mockups. You should always use another pair of eyes to
verify your mockups and add more details to it. You aren’t the only
smart guy in the world you know?
Kabir: I thought I was, ok. What’s next?
Omar: File those user stories in your issue tracking
system in some special category. Say “User Stories” category. What
do you use for your issue tracking system?
Kabir: Flyspray
Omar: Good enough. Create a new project in Filespray
named “User Stories”. File tasks for user stories. Each story, one
task. Attach the mockup to the tasks. Then create one account for
your customer so that customer can login and see the user stories,
make comments, suggest changes etc. You will get the conversation
with your customer recorded as comments in the task. This comes
handy for engineers and for resolving dispute later on. Moreover,
get your customer to prioritize the tasks properly. Understood?
Kabir: I don’t think customer will go through that
trouble. Customer will ask for some word document that has all the
user stories and she will write in the document what are the
changes. I will have to reflect them in Flyspray. Is it really
necessary to file user stories in Flysrpay? Can’t I just maintain
one word doc with customer?
Omar: Absolutely not. Word documents suffer from
versioning problem. You have one version, your customer has another
version, your engineers have another version. it becomes a
nightmare to move around with word docs which has many user stories
in it and keep them in sync all the time. Moreover, referencing a
particular use case also becomes a problem. Say at later stage of
the project, there’s a bug which needs to refer to User Story #123.
You will have to say User Story #123 in
centralserverfileshareuser stories1.doc. Now if
centralserver dies, or you put it somewhere else, all
these references are gone. Don’t go for word doc. Keep everything
on the web that you can refer to it using a URL or small number.
Another problem is numbering stories in Word Doc. Word won’t
produce unique ID for you. You will end up with duplicate user
story numbers. If you use Flyspray, it’s will generate unique ID
for you.
Kabir: OK, let me see how I convince my customer to use
Flyspray.
Omar: Yes, you should. If Flyspray is hard for customers,
use some simple issue tracking system that’s a no-brainer for
non-engineers. Some fancy AJAX based todolist site will be good
enough if it has picture attachment feature and auto task number
feature.
Kabir: OK, I will find such a website. So, I got the user
stories done. Now I show them to customer, review, make changes.
Finally I get customer to sign off on User story #X to #Y for a two
weeks sprint. Then what happens?
Omar: On your first day of sprint, you do a sprint
planning meeting where you present those user stories to your
engineers and ask them to break each story into small tasks and
estimate each task. Make sure no engineer put 1 day or 2 day for
any task. Break them into even smaller tasks like 4 hours of tasks.
This will force your engineers to give enough thought into the
stories and identify possible problems upfront. Generally when
someone says this is going to take a day or two, s/he has no idea
how to do it. S/he has not thought about the steps need to be done
to complete that task. Your are getting an estimate that’s either
overestimated or underestimated. Forcing an engineer to allocate
tasks in less than 4 hours slot makes an engineer think about the
steps carefully.
Kabir: If engineers do this level of estimate, they will
think about each task for at least an hour. This is going to take
days to finish estimating so many tasks. How do you do it in a
day?
Omar: We do 4 hours Planning meeting where Product Owner
explains the stories to engineers and then after 30 mins break,
another 4 hours meeting where engineers pickup stories and breaks
them into tasks and estimate on-the-fly. This 4 hours deadline is
strictly maintained. If Product team cannot explain the tasks for a
sprint in 4 hours, we don’t do the tasks in the sprint. If the
tasks are so complex or there are so many tasks that they cannot be
explained in 4 hours, engineers unlikely to do them within one/two
week long sprint. Similarly if engineers cannot estimate the tasks
in their 4 hours slot, the tasks are just too complex to estimate
and thus have high probability of not getting done in the sprint.
So, we drop them as well.
Kabir: This is impossible! No one’s going to attend 8
hours meeting on a day. Besides, telling them to estimate a task on
the spot is super inefficient. They won’t produce more than 60%
correct estimates. They will give some lump sum estimate and then
go away.
Omar: Incorrect, if engineers cannot make estimates of a
task in 10 to 20 minutes, they don’t have the capability of
estimating at all. If your engineers are habituated to take a task
from you for estimating and then go to their office, talk to their
friends on the phone, drink soda, walk around, gossip with
colleagues and end of the day if they have the mood to sit and
think about the estimate then open a new mail, write some numbers
and email it to you; they better learn to do this on-demand, when
requested, within time constraint. It’s a discipline that they need
to learn and implement in their life. Estimates are something they
do from the moment they wake up to the moment they go to sleep.
Besides, the planning meeting is the best place to estimate tasks –
all engineers are there, product team is there, your architects
should be there, QA team is there. It’s easy to ask questions, get
ideas and helps from others.
Kabir: I have engineers who just can’t do well under
pressure. They need some undisturbed moment, where they can sit and
think about tasks without anyone staring at them.
Omar: Train them to learn how to keep their head cool and
do their job in the midst of attention. Anyway, let’s stop talking
about these auxiliary issues and talk about the most important
issues. Where were we?
Kabir:About dropping tasks, I already negotiated with
customer that we are going to do story A, B, C in this sprint. Now
after the sprint planning meetings, engineers say they can’t do B.
Problem is I have already committed to deliver A, B, and C to
customer within 2 weeks and sent him the invoice. How do I handle
this?
Omar: How do you commit when you don’t know how long A,
B, and C are going to take?
Kabir: Customer tells me to do A, B, C within two weeks.
And after doing some preliminary discussion with engineers, I
commit to customer and then do the sprint planning meeting. I
can’t wait until the sprint meeting is done and developers
have given me estimates of all the tasks.
Omar: Wrong. You commit to customer after the sprint
planning meeting is done. Before that, you give customer just a
list of things that you believe you can try to do in following two
weeks. Tell customer that you will be able to confirm after the
sprint planning meeting. The time to do a sprint meeting is only 8
hours = a day. So, end of the day, you have some concrete stuff to
commit to customer. From your model where you give engineers days
to estimate, it won’t work. You have to finish planning
within a day and end of the day, commit to customer.
Kabir: What if customer does not agree? What if he says,
“I must get A, B and C in two weeks, otherwise I am going somewhere
else?”
Omar: This is a hard situation. I am tempted to say that
you tell your customer, “Go away!”, but in reality you can’t. You
have to negotiate and come to a mutual agreement. You cannot just
obey customer and say “Yes Mi Lord, we will do whatever you say”
because you clearly cannot do it. The fact is, end of the sprint,
you *will* get only A and C done and B not done. Then customer will
Fedex you his shoes so that you can ask someone to kick you with
it.
Kabir: Correct, so what do I do?
Omar: There are tricky solutions and non-tricky honest
solutions to this. Tricky solution is, say you engaged 5 engineers
in the project who can get A and C done in time. But you realize
you need another engineer to do B, otherwise there’s no way you can
finish A, B and C in two weeks. So, you invoice customer with 6
engineers and get A, B and C done. Now customer may not agree with
you paying for the 6th engineer. Then you do a clever trick. You
engage the 6th engineer free of cost in this sprint. Don’t tell
customer that there’s an extra head working in the project. Or you
can tell customer that out of good will, you want to engage another
engineer free of cost to make sure customer gets a timely delivery.
This boosts your image. Later on, when you get a sprint that’s more
or less relaxed and 4 engineers can do the job, you secretly engage
one engineer to some other project but still charge for 5 engineers
to your customer. This way you cover the cost for the 6th
engineer that you secretly engaged earlier sprint. This is dirty.
But when you have so hard a** customer who’s forcing you “what”,
“when” and “how” all at the same time and not open to negotiation,
you have no choice but to do these dirty tricks. You can also add
extra one hour to every task for every engineer in a sprint or add
some vague tasks like “Refactor User object to allow robust login”.
This way you will get quite some amount of extra hours that will
compensate for the hidden free engineer that you engage. You get
the idea right?
Kabir: Ingenious! And what’s the honest and clear way to
do these?
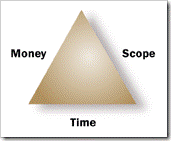
Omar: You negotiate with customer. You tell your customer
that he or she can only have any two choices from Money-Scope-Time.
This is called the project management triangle. Do you know about
this?
Kabir: Googling…
Omar: Read this article:
http://office.microsoft.com/en-us/project/HA010211801033.aspx
It shows a triangle like this:
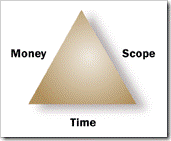
So, your customer can specify any two. If customer specifies
Scope and Time (“what” and “when”), then customer must be flexible
on Money or “how” you do it within those two constraints. If
customer specifies Money and Scope, then you are free to decide on
time. You engage lower resource and take more time to get things
done. Got the idea?
Kabir: Yes, understood. Nice, I can show this to customer
and educate him. Is there any book for the evil tricks that you
just gave me?
Omar: No, I might write one soon. I will name it
“Customers are evil, so be you”.
Raisul: Hey, I have fixed people engaged in a project. I can’t
change the number of people sprint-to-sprint to compensate for
change in money. So, the triangle does not work for me. What do I
do here?
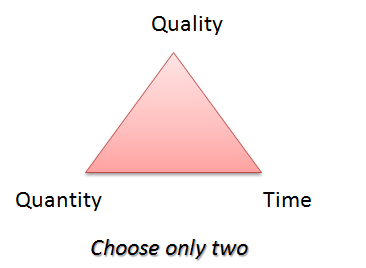
Omar: Right. I also made a slightly different version of
it. Here’s my take:
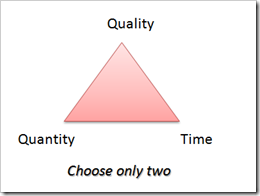
This is for situation where you have fixed resource engaged for
a particular customer. In that case, you cannot reduce people
on-demand because you cannot reassign them. Such a case requires
different strategy. If customer forces you Quality and Time,
customer must be willing to sacrifice Quantity. Customer cannot
say, produce perfect login form in 2 weeks and add cool ajax
effects to it. Customer has to sacrifice cool ajax effects, or
sacrifice *perfection* of login form, or sacrifice number of
days.
From the above two triangles, which one’s more appropriate for
you?
Kabir: Second one because customer hires 5 engineers from
me. I cannot take one away and engage in a different project. Well,
not openly of course.
Omar: OK, sounds fair. What else do you need from me?
Kabir: Let me think about all these. This is definitely
worth thinking. I have to figure out whether to play fair or play
clever. End of the day, I need to produce great product, so that, I
get good recommendation and future projects from customer. So, I
need to do whatever it takes. It’s hard to run an offshore dev shop
where we kinda have to work like slaves and like a bunch of zombies
mumble every 10 mins – “Customer is always right”. You are very
lucky to have your own company.
Omar: I had two offshore dev shops before Pageflakes. I know how it feels.
Wish you good luck. I have seen your product, you guys are building
a great ASP.NET MVC+jQuery application. Release it. It’s worth
showcasing.
Raisul: Thank you very much. See ya…
(End of chat)
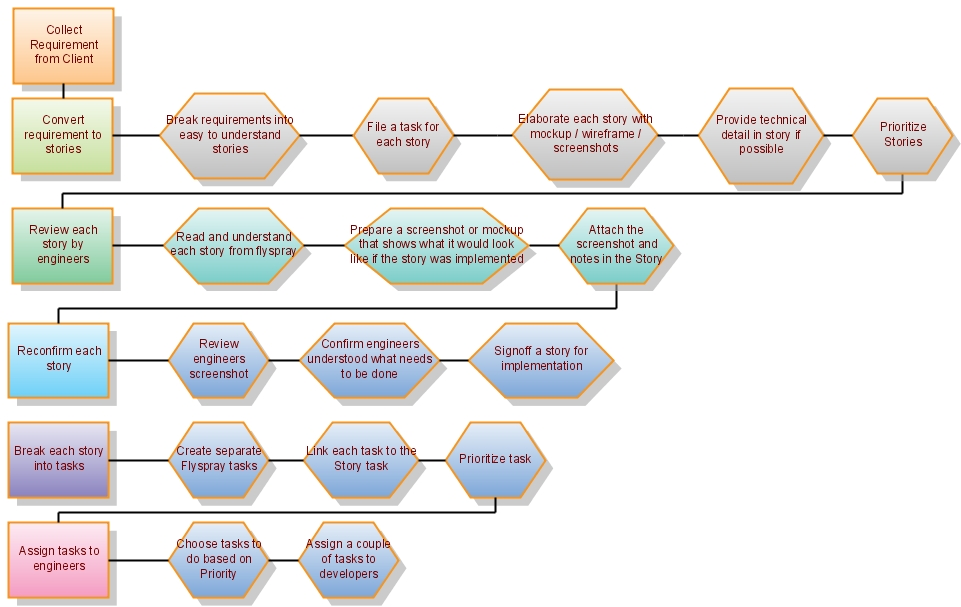
This is the diagram my friend produced, which shows the steps to
do before a sprint is started:
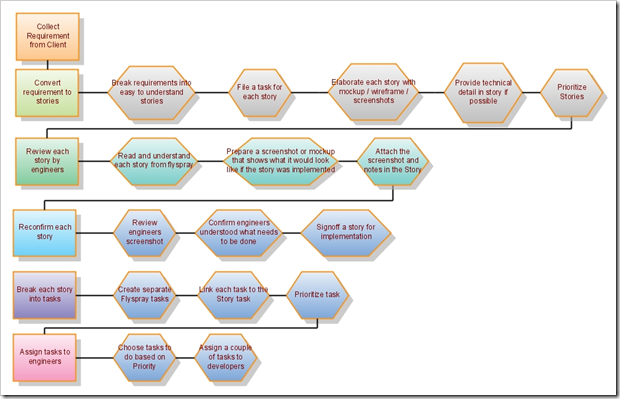
Handy for Product Managers. Enlightening for developers.