Generally we put static content (images, css, js) of our website
inside the same web project. Thus they get downloaded from the same
domain like www.dropthings.com. There are three
problems in this approach:
- They occupy connections on the same domain www.dropthings.com and thus other
important calls like Web service call do not get a chance to happen
earlier as browser can only make two simultaneous connections per
domain. - If you are using ASP.NET Forms Authentication, then you have
that gigantic Forms Authentication cookie being sent with every
single request on www.dropthings.com. This cookie
gets sent for all images, CSS and JS files, which has no use for
the cookie. Thus it wastes upload bandwidth and makes every request
slower. Upload bandwidth is very limited for users compared to
download bandwidth. Generally users with 1Mbps download speed has
around 128kbps upload speed. So, adding another 100 bytes on the
request for the unnecessary cookie results in delay in sending the
request and thus increases your site load time and the site feels
slow to respond. - It creates enormous IIS Logs as it records the cookies for each
static content request. Moreover, if you are using Google Analytics
to track hits to your site, it issues four big cookies that gets
sent for each and every image, css and js files resulting in slower
requests and even larger IIS log entries.
Let’s see the first problem, browser’s two connection limit. See
what happens when content download using two HTTP requests in
parallel:
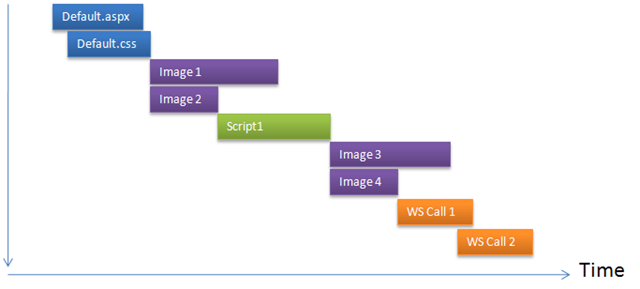
This figure shows only two files are downloaded in parallel. All
the hits are going to the same domain e.g. www.dropthings.com. As you see,
only two call can execute at the same time. Moreover, due to
browser’s way of handling script tags, once a script is being
downloaded, browser does not download anything else until the
script has downloaded and executed.
Now, if we can download the images from different domain, which
allows browser to open another two simultaneous connections, then
the page loads a lot faster:
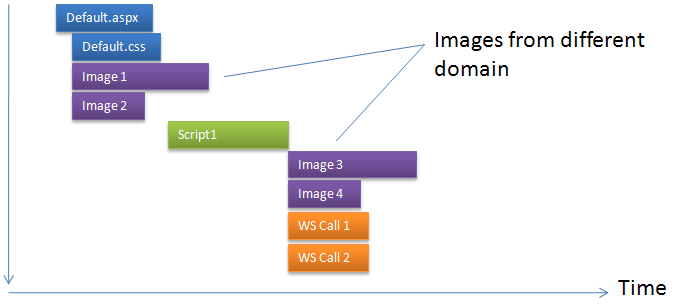
You see, the total page downloads 40% faster. Here only the
images are downloaded from a different domain e.g.
“s.dropthings.com”, thus the calls for the script, CSS and
webservices still go to main domain e.g. www.dropthings.com
The second problem for loading static content from same domain
is the gigantic forms authentication cookie or any other cookie
being registered on the main domain e.g. www subdomain. Here’s how
Pageflake’s website’s request looks like with the forms
authentication cookie and Google Analytics cookies:
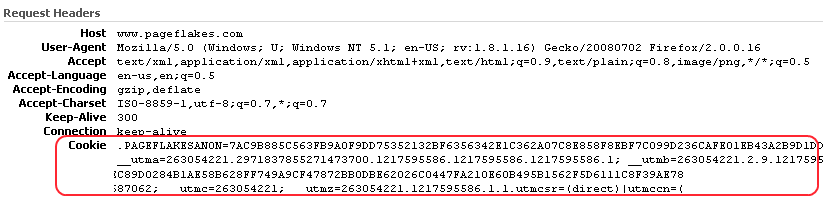
You see a lot of data being sent on the request header which has
no use for any static content. Thus it wastes bandwidth, makes
request reach server slower and produces large IIS logs.
You can solve this problem by loading static contents from
different domain as we have done it at Pageflakes by loading static
contents from a different domain e.g. flakepage.com. As the cookies
are registered only on the www subdomain, browser does not send the
cookies to any other subdomain or domain. Thus requests going to
other domains are smaller and thus faster.
Would not it be great if you could just plugin something in your
ASP.NET project and all the graphics, CSS, javascript URLs
automatically get converted to a different domain URL without you
having to do anything manually like going through all your ASP.NET
pages, webcontrols and manually changing the urls?
Here’s a nice HttpFilter that will do the exact thing.
You just configure in your web.config what prefix you want
to add in front of your javascript, css and images and the filter
takes care of changing all the links for you when a page is being
rendered.
First you add these keys in your web.config‘s
before the relative URL of your static content. You can define
three different prefix for images, javascripts and css:

So, you can download images from one domain, javascripts from
another domain and css from another domain in order to increase
parallel download. But beware, there’s the overhead of DNS lookup
which is significant. Ideally you should have max three unique
domains used in your entire page, one for the main domain and two
other domain.
Then you register the Filter on Application_BeginRequest
so that it intercepts all aspx pages:
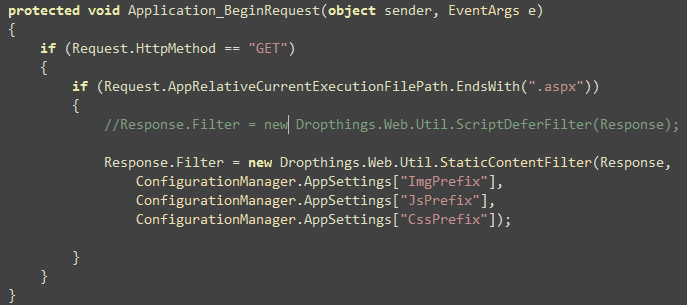
That’s it! You will see all the tag’s
src attribute, < script> tag’s src
attribute, tag’s href attribute are
automatically prefixed with the prefix defined in
web.config
Here’s how the Filter works. First it intercepts the
Write method and then searches through the buffer if there’s
any of the tags. If found, it checks for the src or
href attribute and then sees if the URL is absolute or
relative. If relative, inserts the prefix first and then the
relative value follows.
The principle is relatively simple, but the code is far more
complex than it sounds. As you work with char[] in an
HttpFilter, you need to work with char[] array only,
no string. Moreover, there’s very high performance
requirement for such a filter because it processes each and every
page’s output. So, the filter will be processing megabytes of data
every second on a busy site. Thus it needs to be extremely fast. No
string allocation, no string comparison, no Dictionary or
ArrayList, no StringBuilder or MemoryStream.
You need to forget all these .NET goodies and go back to good old
Computer Science school days and work with arrays, bytes, char and
so on.
First, we run through the content array provided and see if
there’s any of the intended tag’s start.
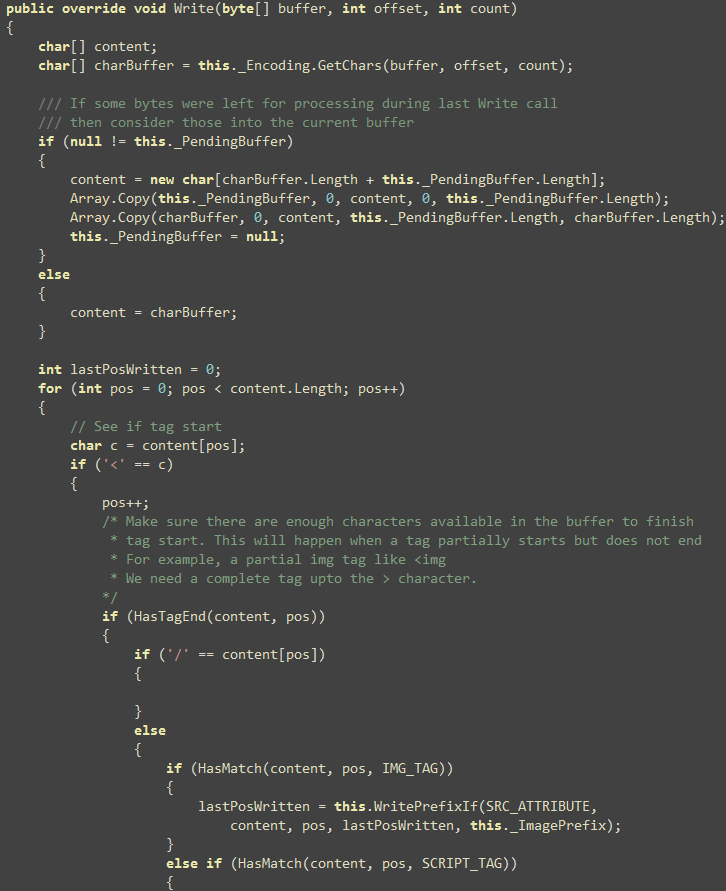
Idea is to find all the image, script and link tags and see what
their src/href value is and inject the prefix if needed. The
WritePrefixIf(…) function does the work of parsing the
attribute. Some cool things to notice here is that, there’s
absolutely no string comparison here. Everything is done on the
char[] passed to the Write method.
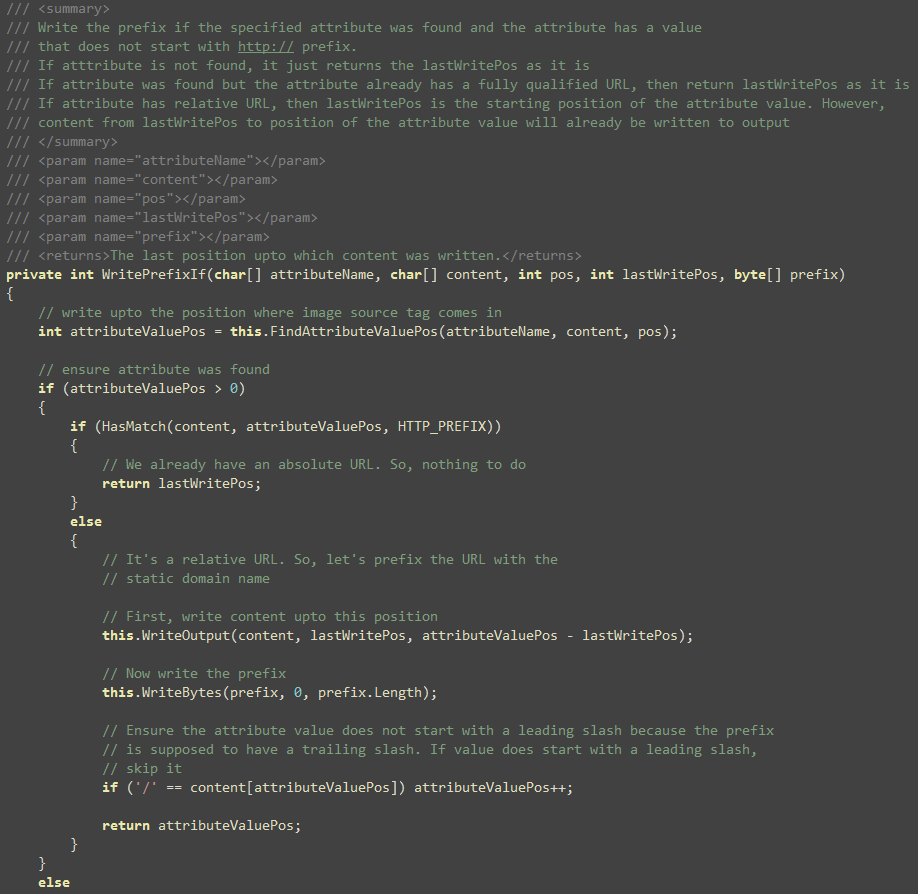
This function checks if src/href attribute is found and
it writes the prefix right after the double quote if the value of
the prefix does not start with http://
Basically that’s it. The only other interesting thing is the
FindAttributeValuePos. It checks if the specified attribute
exists and if it does, finds the position of the value in the
content array so that content can be flushed up to the value
position.
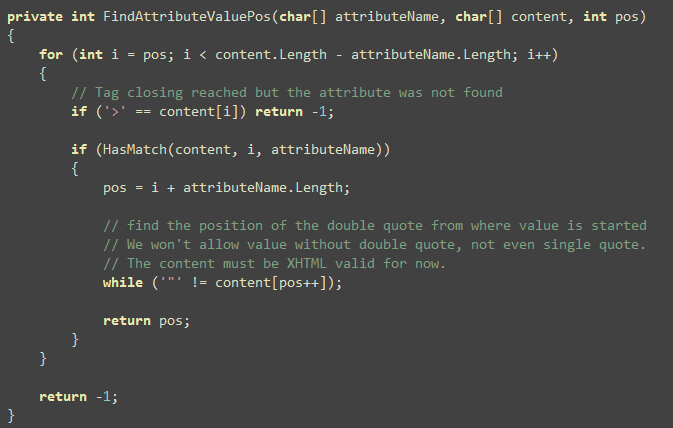
Two other small functions that are worth mentioning are the
compare functions so that you can see, there’s absolutely no string
comparison involved in this entire filter:
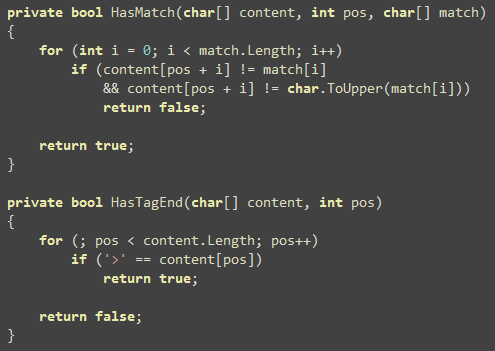
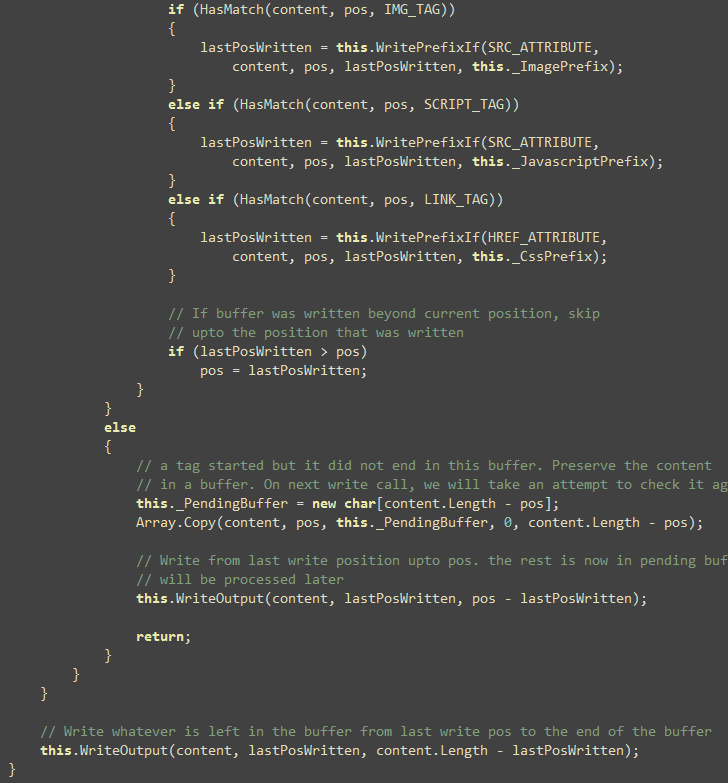
Now the season finally, the remaining code in Write function
that solves several challenges like unfinished tags in a buffer.
It’s possible Write method will pass you a buffer where a tag has
just started, but did not end. Of you can get part of a tag like
handled. Idea is to detect such unfinished tags and store them in a
temporary buffer. When next Write call happens, it will
combine the buffer and process it.
That’s it for the filter’s code.
Download the code
from here. It’s just one class.
You can use this filter in conjunction with the
ScriptDeferFilter that I have showed in CodeProject
article which defers script loading after body and combines
multiple script tags into one for faster download and better
compression and thus significantly faster web page load
performance.
In case you are wondering whether this is production
ready, visit www.dropthings.com and you will see
static content downloads from s.dropthings.com using this
Filter.
| Share this post : |  |
 |
 |
 |
 |
 |
 |
 |
 |

Sir, when i change tab, it cause
Sys.InvalidOperationException: Type Sys.Timer has already been registered. The type may be defined multiple times or the script file that defines it may have already been loaded. A possible cause is a change of settings during a partial update.
and then cause
Sys.ScriptLoadFailedException: The script 'Dropthings/ScriptResource.axd?d=BXy0sUJnDxvhNpnqhqnaXanryycCjH5Sc9VOYngMd-w6l–Oa0jwVZUimP9aK7tg0ZTgLJtH0Ow89DsNxlRZQg2&t=633475145180000000' failed to load. Check for: Inaccessible path. Script errors. (IE) Enable 'Display a notification about every script error' under advanced settings. Missing call to Sys.Application.notifyScriptLoaded().
Coulde you finger out i should focus where ? Thanks.
Can we use regex expression to match src,href attributes Wouldn't it be faster?
I found ScriptResource.axd will load twice when postback!
Thanks for writing all this up! It's nice to have it all figure out. Seems like lots of picky stuff I could get wrong.
Hi Omar,
I want to display an external Image provided from a URL on my web site asynchronously so that it wont effect my current flow of the site.
Please help me out…
Regards.
Can we use regex expression to match src,href attributes Wouldn't it be faster?
Greetings to mankind!
What would happen if you changed all your reference uris in the code itself. So instead of
img src=”foo.org/img/bar.jpg” or
img src=”~/img/bar.jpg”
you could write:
img src=”s.foo.org/img/bar.jpg” or even the ip
img src=”123.456.789/s.foo.org/img/bar.jpg”
I guess this could be a nightmare for maintenance but i wonder if it is better because this way you do not have to remap every link with the function on Application_BeginRequest – less load on the server
you know bro, after reading this article i integrated with our rails application.
as i see you had to do a lot of stuffs to enable this feature. but surprising in rails, this option was already bundle with default framework package in a configuration layer.
so i just needed setting the url pattern. now my server is serving image and static content from 4 different asset domains.
so i have 8 connections ready for serving my static contents.
let's check out here http://www.somewhereinads.net
since my server is using ETag properly i don't think i should worry about different domain.
best wishes,
Interesting, does Rail intercept execution of every dynamic page and automatically parse the content being sent and figure out the image urls and replace them?
If it does, then that's cool. However, there's a problem of having everything nicely packaged into chocolate boxes. You don't know how those chocolates are made from. You just blindly put them on your mouth and enjoy the taste. If it's bitter, you cannot add more sugar to it. You have to live with it. But if you could make the chocolate yourself, you could add as much sugar as you like.
The problem with such URL pattern matching is that the entire response needs to be stored in a buffer so that a pattern search, which is most probably a regex search, needs to be performed on the entire response buffer. Moreover, replacing strings in a buffer means more temporary buffers.
Now if you page is producing a 200 KB output, it's storing that entire 200 KB in a buffer and running a regex over 200 KB, which is very slow.
This is why I went great lenths to ensure there's absolutely no buffering of response. The response is processed as every character is written to the stream.
hi bro,
i think my last response is lost. anyway i am writing it again 🙂
in rails actually we don't write any hardcoded url rather we use named based mapping from routing configuration.
ie. <%= profile_url(@user) %>
this may product – /user/profile/omar
let's say our requirement came up where we are suggested to add locale information with in the url.
so rather changing every consumer code, we put the change on the routing configuration.
so <%= profile_url(@user) %> will now return /en/user/profile/omar
similarly every url are produced through helper function.
for example, if we want to product tag we would use <%= javascript_tag_include ... %> same goes for css, image and others.
more precisely every url are produced by calling “url_for” method.
so you can understand how a simple abstraction can ensure a lot of way to improve it.
actually rails came out with the live product from 37singles. i guess to improve their own product quality they introduced may stuffs, dynamic url configuration is one of them.
as you mentioned – “You don't know how those chocolates are made from”
i doubt it, since we separate developer in two groups, 1. passionate developer, 2. general developer.
so i guess, in my rails team we have a good practice keeping eyes on rails trunk. so we now whats going and how it works.
btw, i think you know about open class concept.
where class can be edited (in scope or none scope). i guess .NET started with class extension support though this is not exactly open class but better in conservative platform.
by default ruby classes are compliant with open class. so you can add your patch or modification or fixes or add new method in any scope of your code base.
so i think, adding sugar is not a big problem at all since ruby is born to enable it 🙂
thanks for your time and patients.
Using functions to produce URL is a very good concept. If you do it in any platform, whether PHP, JSP, ASP.NET, it solves the problem of making URLs configuration driven. This is not a unique feature of ROR. Every platform already has this support. YOu can do this in PHP, JSP, ASP.NET
Or just use a whole function to produce script tags.
<%= MakeScriptTag('gaga.js', 'text/javascript') %>
However, you can't always make all Javascript, CSS, Images generate from such functions because then you don't get designer support. You cannot have a page full of those functions instead of any image, script or javascript tag and show it nicely on a designer. The designer will simply show garbage. Thus your designer will not be able to design the page at all. Only developers, with ROR installed and has a running project on webserver, can then design the page because they can write such functions and see the result on browser.
The solution I have shown here allows you to keep using traditional html tags and still have the url conversion feature done on-the-fly. You don't need to use any function to generate url, which does not mean you can't, you can always use functions to generate urls for links, images, css and javascripts. But if you are working with a designer, and s/he gives you html snippet without any dynamic code in it, then you use this solution to make things work. Not everyone has the luxury to engage developers do the html designing. There are non-programmer designers who needs to design pages. For them, using dynamic code on the design is a big no no. Moreover, there should be clear separation of design and code. Using functions inline within html hampers that. Then you have dynamic code spread throughout your page where you should have clear separation of static and dynamic code.
further discussing about why rails routing concept is unique than normal function based approach. i would refer u the following url – guides.rails.info/…/routing_outside_in.html
well, my question is, do you or your team keep the same HTML file which was complied by the designer or design team?
in our company, our designer prefers to submit his work in a single html file, where every visual elements are designed.
so later we separate them in 3 basic files.
1. the layout (which you can call like theme)
2. the action template (which are used with the controller)
3. the fragment template (this is reusable template, which are used from the action template)
as you know, you don't only write url in your view, you do it sometimes in controller as well.
let's say you wants to redirect to a specific URL after performing some action.
i guess in .NET you would do it in 3 ways –
1. writing the hardcoded url ie. Redirect “/url/bla”
2. or using the constant ie. Redirect USER_ACTION_SUCCESS
3. or using the map object ie. Redirect mUrlMapping.get(USER_ACTION);
the later approach has good chance to propagate the fastest change impact, though i believe keeping Map object with the key value pair will provide more flexibility.
but in rails we would write in controller –
redirect_to uesr_my_page_url
so you see, in rails it has less chance of introducing bug with this simple approach.
since human does error we can't say we won't do that. so we rather follow something that can assist us to get away from common errors.
i would say in such a case rails url abstraction with routing is a great option.
thanks bro.
u are my man. great code. fantastic idea and thought process. thanks mate.
i have a doubt regarding performance issue of this approach.
we have a page with 20-30 images(small and big),100+ controls( having 2-4 grid with 2-3 images in every rows) and around 200 -300 users are requesting same page at a time.
Regards
Rakesh
Hi Omar… I tryied your filter but as I try to load the page I get 3 errors, the first is
“ASP.NET Ajax client-side framework failed to load.”
The page I'm generating is composed of a master page and some usercontrols… one is using ajax toolkit…
Any suggestion?
Thanks in advance
Paolo
hi omar,
ur code seems to good…but i found out some issues with that like when i am calling an ajax method,the images are not getting loaded prop
for that i have added this code also
if (Request.AppRelativeCurrentExecutionFilePath.EndsWith(“.aspx”) || Request.AppRelativeCurrentExecutionFilePath.EndsWith(“.axd”))
i found still the issue exists…am really struck wth this issue
Hai omar,
When i use static content filter class ajax clienside frame work failed to load.. Plz reply me to my mail id psc_pandiya@yahoo.co.in
Hi Omar,
What happens if you reference images or css such as http://www.mysite.com/../foo/bar.jpg ? notice it has the relative path there
http://www.mysite.com/../foo/bar.jpg ? notice it has the relative path there
Regards Rob
I cant loud this script
I’m workin with GetResponseStream() method of HttpWebResponse object and It works 100% from me.
Here an example:
====================================================
protected void Button1_Click(object sender, EventArgs e)
{
LoadImage(“http://www.google.com.br/intl/en_com/images/srpr/logo1w.png”);
}
private void LoadImage(string pImageUrl)
{
System.IO.Stream receiveStream = null;
try
{
System.Net.WebProxy wp = null;
wp = new System.Net.WebProxy();
wp.UseDefaultCredentials = true;
System.Net.HttpWebRequest webRequest = (System.Net.HttpWebRequest)System.Net.WebRequest.Create(pImageUrl);
webRequest.Proxy = wp;
System.Net.HttpWebResponse webResponse = (System.Net.HttpWebResponse)webRequest.GetResponse();
receiveStream = webResponse.GetResponseStream();
System.Drawing.Bitmap bmpImage = new System.Drawing.Bitmap(receiveStream);
Response.Clear();
Response.Buffer = true;
Response.ContentType = “image/jpeg”;
bmpImage.Save(Response.OutputStream, System.Drawing.Imaging.ImageFormat.Jpeg);
}
catch { throw; }
}
====================================================
I found a bug.
When there no prefix for scripts, the script src lost the preceding /.
eg.
which should be
when a page which owns a ScriptManager is not in the root path, an error sys not found occurs.
Hope you can fix the bug.
WebResource.axd?d=8suyW_5-CeGaR46BxmDouw2&t=633802945995006876″ type=”text/javascript
lost the preceding slash /.
I’m using this class in a web site with GZIP compression enabled, and the class make the pages not working.
Someone could help?
How did you enable GZIP?
Hello, thanks for your answer.
The following is my code in Global.asax for GZIP.
————————————————————————————–
private void Application_PostReleaseRequestState(object sender, EventArgs e)
{
//Prendiamo l’oggetto HttpApplication
HttpApplication app = (HttpApplication)sender;
//Il MIME type della risorsa restituita
string strContentType = app.Response.ContentType.ToLower();
//Variabile che conterrà l’header Accept-Encoding del client
string strAcceptEncoding = null;
//Usiamo una classe interna di ASP .Net per avere il valore dell’header Accept-Encoding
HttpWorkerRequest worker = (HttpWorkerRequest)((IServiceProvider)app.Context).GetService(typeof(HttpWorkerRequest));
//((IServiceProvider)app.Context).GetService(typeof(HttpWorkerRequest));
strAcceptEncoding = worker.GetKnownRequestHeader(HttpWorkerRequest.HeaderAcceptEncoding);
//Metodo meno efficiente per avere l’header Accept-Encoding
//strAcceptEncoding = app.Request.Headers(“Accept-Encoding”)
//Controlliamo che la richiesta corrente
//1) accetti qualche forma di compressione
//2) contenga qualche formato testuale, javascript o XML
//3) non sia una richiesta AJAX
//if (!string.IsNullOrEmpty(strAcceptEncoding) &&
// (strContentType.EndsWith(“javascript”) ||
// strContentType.StartsWith(“text/”) ||
// strContentType.EndsWith(“xml”)) &&
// app.Context.Request[“HTTP_X_MICROSOFTAJAX”] == null)
if (!string.IsNullOrEmpty(strAcceptEncoding)
&& (
string.Compare(strContentType, “text/html”, true) == 0
/*||
string.Compare(strContentType, “text/css”, true) == 0*/
/*||
string.Compare(strContentType, “application/x-javascript”, true) == 0
||
(strContentType.EndsWith(“javascript”) && !app.Request.AppRelativeCurrentExecutionFilePath.EndsWith(“.translated”))*/
)
&& app.Context.Request[“HTTP_X_MICROSOFTAJAX”] == null)
{
strAcceptEncoding = strAcceptEncoding.ToLower();
//Se il client supporta gzip
if (strAcceptEncoding.Contains(“gzip”) || strAcceptEncoding == “*”)
{
//Aggiungiamo un filtro di compressione GZip al responso
//basandoci su quello originale (dati non compressi)
app.Response.Filter = new System.IO.Compression.GZipStream(app.Response.Filter, System.IO.Compression.CompressionMode.Compress);
//Aggiungiamo l’header Content-Encoding che informa il client
//che il contenuto è compresso con gzip
app.Response.AppendHeader(“Content-Encoding”, “gzip”);
}
else if (strAcceptEncoding.Contains(“deflate”))
{
//Come prima ma utilizziamo l’algoritmo deflate
app.Response.Filter = new System.IO.Compression.DeflateStream(app.Response.Filter, System.IO.Compression.CompressionMode.Compress);
app.Response.AppendHeader(“Content-Encoding”, “deflate”);
}
}
}
Great code! I was wondering how can I implement this on MVC? especially when checking ASPX page extension:
if (Request.AppRelativeCurrentExecutionFilePath.EndsWith(“.aspx”)) { … }
Thanks
I would like to do something similar to this based off of your work, but all the images are broken so I can’t see what you did…do you have a github for it or have the images you can send?