When your database tables start accumulating thousands of rows
and many users start working on the same table concurrently, SELECT
queries on the tables start producing lock contentions and
transaction deadlocks. This is a common problem in any high volume
website. As soon as you start getting several concurrent users
hitting your website that results in SELECT queries on some large
table like aspnet_users table that are also being updated
very frequently, you end up having one of these errors:
Transaction (Process ID ##) was deadlocked on lock resources
with another process and has been chosen as the deadlock victim.
Rerun the transaction.
Or,
Timeout Expired. The Timeout Period Elapsed Prior To Completion
Of The Operation Or The Server Is Not Responding.
The solution to these problems are – use proper index on
the table and use transaction isolation level Read
Uncommitted or WITH (NOLOCK) in your SELECT queries. So,
if you had a query like this:
SELECT * FORM aspnet_users
where ApplicationID =’xxx’ AND LoweredUserName = 'someuser'
You should end up having any of the above errors under high
load. There are two ways to solve this:
SET TRANSACTION LEVEL READ UNCOMMITTED;
SELECT * FROM aspnet_Users
WHERE ApplicationID =’xxx’ AND LoweredUserName = 'someuser'
Or use the WITH (NOLOCK):
SELECT * FROM aspnet_Users WITH (NOLOCK)
WHERE ApplicationID =’xxx’ AND LoweredUserName = 'someuser'
The reason for the errors are that since aspnet_users is
a high read and high write table, during read, the table is
partially locked and during write, it is also locked. So, when the
locks overlap on each other from several queries and especially
when there’s a query that’s trying to read a large
number of rows and thus locking large number of rows, some of the
queries either timeout or produce deadlocks.
Linq to Sql does not produce queries with the WITH
(NOLOCK) option nor does it use READ UNCOMMITTED. So, if
you are using Linq to SQL queries, you are going to end up with any
of these problems on production pretty soon when your site becomes
highly popular.
For example, here’s a very simple query:
using (var db = new DropthingsDataContext()) { var user = db.aspnet_Users.First(); var pages = user.Pages.ToList(); }
DropthingsDataContext is a DataContext built from Dropthings database.
When you attach SQL Profiler, you get this:
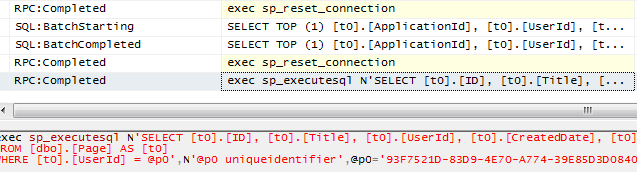
You see none of the queries have READ UNCOMMITTED or WITH
(NOLOCK).
The fix is to do this:
using (var db = new DropthingsDataContext2()) { db.Connection.Open(); db.ExecuteCommand("SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;"); var user = db.aspnet_Users.First(); var pages = user.Pages.ToList(); }
This will result in the following profiler output

As you see, both queries execute within the same connection and
the isolation level is set before the queries execute. So, both
queries enjoy the isolation level.
Now there’s a catch, the connection does not close. This
seems to be a bug in the DataContext that when it is disposed, it
does not dispose the connection it is holding onto.
In order to solve this, I have made a child class of the
DropthingsDataContext named DropthingsDataContext2
which overrides the Dispose method and closes the
connection.
class DropthingsDataContext2 : DropthingsDataContext, IDisposable { public new void Dispose() { if (base.Connection != null) if (base.Connection.State != System.Data.ConnectionState.Closed) { base.Connection.Close(); base.Connection.Dispose(); } base.Dispose(); } }
This solved the connection problem.
There you have it, no more transaction deadlock or lock
contention from Linq to SQL queries. But remember, this is only to
eliminate such problems when your database already has the right
indexes. If you do not have the proper index, then you will end up
having lock contention and query timeouts anyway.
There’s one more catch, READ UNCOMMITTED will return rows
from transactions that have not completed yet. So, you might be
reading rows from transactions that will rollback. Since
that’s generally an exceptional scenario, you are more or
less safe with uncommitted read, but not for financial applications
where transaction rollback is a common scenario. In such case, go
for committed read or repeatable read.
There’s another way you can achieve the same, which seems
to work, that is using .NET Transactions. Here’s the code
snippet:
using (var transaction = new TransactionScope( TransactionScopeOption.RequiresNew, new TransactionOptions() { IsolationLevel = IsolationLevel.ReadUncommitted, Timeout = TimeSpan.FromSeconds(30) })) { using (var db = new DropthingsDataContext()) { var user = db.aspnet_Users.First(); var pages = user.Pages.ToList(); transaction.Complete(); } }
Profiler shows a transaction begins and ends:
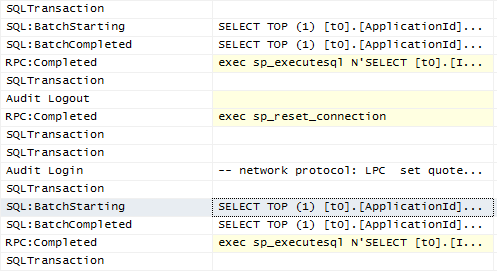
The downside is it wraps your calls in a transaction. So, you
are unnecessarily creating transactions even for SELECT operations.
When you do this hundred times per second on a web application,
it’s a significant over head.
Some really good examples of deadlocks are given in this
article:
http://www.code-magazine.com/article.aspx?quickid=0309101&page=2
I highly recommend it.