Recently after Load Testing my open source project Dropthings, I
encountered a lot of memory leak. I found lots of Workflow
Instances and Linq Entities were left in memory and never
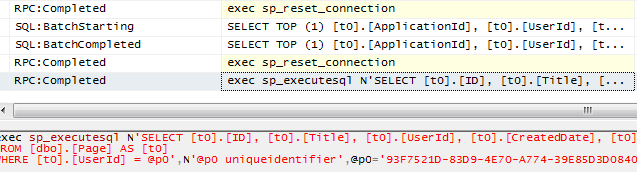
collected. After profiling the web application using .NET Memory Profiler, it showed the real picture:

It shows you that instances of the several types are being
created but not being removed. You see the “New” column
has positive value, but the “Remove” column has 0. That
means new instances are being created, but not removed. Basically
the way you do Memory Profiling is, you take two snapshots. Say you
take one snapshot when you first visit your website. Then you do
some action on the website that results in allocation of objects.
Then you take another snapshot. When you compare both snapshots,
you can see how many instances of classes were created between
these two snapshots and how many were removed. If they are not
equal, then you have leak. Generally in web application many
objects are created on every page hit and the end of the request,
all those objects are supposed to be released. If they are not
released, then we have a problem. But that’s the scenario for
desktop applications because in a desktop application, objects can
remain in memory until app is closed. But you should know best from
the code which objects were supposed to go out of scope and get
released.
For beginners, leak means objects are being allocated but not
being freed because someone is holding reference to the objects.
When objects leak, they remain in memory forever, until the process
(or app domain) is closed. So, if you have a leaky website, your
website is continuously taking up memory until it runs out of
memory on the web server and thus crash. So, memory leak is a bad
– it prevents you from running your product for long duration
and requires frequent restart of app pool.
So, the above screenshot shows Workflow and Linq related classes
are not being removed, and thus leaking. This means somewhere
workflow instances are not being released and thus all workflow
related objects are remaining. You can see the number is same 48
for all workflow related objects. This is a good indication that,
almost every instance of workflow is leaked because there were
total 48 workflows created and ran. Moreover it indicates we have a
leak from a top Workflow instance level, not in some specific
Activity or somewhere deep in the code.
As the workflows use Linq stuff, they held reference to the Linq
stuffs and thus the Linq stuffs leaked as well. Sometimes you might
be looking for why A is leaking. But you actually end up finding
that since B was holding reference to A and B was leaking and thus
A was leaking as well. This is sometimes tricky to figure out and
you spend a lot of time looking at the wrong direction.
Now let me show you the buggy code:
ManualWorkflowSchedulerService manualScheduler =
workflowRuntime.GetService<ManualWorkflowSchedulerService>();
WorkflowInstance instance = workflowRuntime.CreateWorkflow(workflowType, properties);
instance.Start();
EventHandler<WorkflowCompletedEventArgs> completedHandler = null;
completedHandler = delegate(object o, WorkflowCompletedEventArgs e)
{
if (e.WorkflowInstance.InstanceId == instance.InstanceId) // 1. instance
{
workflowRuntime.WorkflowCompleted -= completedHandler; // 2. terminatedhandler
// copy the output parameters in the specified properties dictionary
Dictionary<string,object>.Enumerator enumerator =
e.OutputParameters.GetEnumerator();
while( enumerator.MoveNext() )
{
KeyValuePair<string,object> pair = enumerator.Current;
if( properties.ContainsKey(pair.Key) )
{
properties[pair.Key] = pair.Value;
}
}
}
};
Exception x = null;
EventHandler<WorkflowTerminatedEventArgs> terminatedHandler = null;
terminatedHandler = delegate(object o, WorkflowTerminatedEventArgs e)
{
if (e.WorkflowInstance.InstanceId == instance.InstanceId) // 3. instance
{
workflowRuntime.WorkflowTerminated -= terminatedHandler; // 4. completeHandler
Debug.WriteLine( e.Exception );
x = e.Exception;
}
};
workflowRuntime.WorkflowCompleted += completedHandler;
workflowRuntime.WorkflowTerminated += terminatedHandler;
manualScheduler.RunWorkflow(instance.InstanceId);
Can you spot the code where it leaked?
I have numbered the lines in comment where the leak is
happening. Here the delegate is acting like a closure
and those who are from Javascript background know closure is evil.
They leak memory unless very carefully written. Here the
delegate keeps a reference to the
instance object. So, if somehow delegate
is not released, the instance will remain in memory
forever and thus leak. Now can you find a situation when the
delegate will not be released?
Say the workflow completed. It will fire the completeHandler. But the
completeHandler will not release the
terminateHandler. Thus the
terminateHandler remains in memory and it also holds
reference to the instance. So, we have a leaky
delegate leaking whatever it is holding onto outside
it’s scope. Here the only thing outside the scope if the
instance, which it is tried to access from the parent
function.
Since the workflow instance is not released, all the properties
the workflow and all the activities inside it are holding onto
remains in memory. Most of the workflows and activities expose
public properties which are Linq Entities. Thus the Linq Entities
remain in memory. Now Linq Entities keep a reference to the
DataContext from where it is produced. Thus we have
DataContext remaining in memory. Moreover,
DataContext keeps reference to many internal objects
and metadata cacahe, so they remain in memory as well.
So, the correct code is:
ManualWorkflowSchedulerService manualScheduler =
workflowRuntime.GetService<ManualWorkflowSchedulerService>();
WorkflowInstance instance = workflowRuntime.CreateWorkflow(workflowType, properties);
instance.Start();
var instanceId = instance.InstanceId;
EventHandler<WorkflowCompletedEventArgs> completedHandler = null;
completedHandler = delegate(object o, WorkflowCompletedEventArgs e)
{
if (e.WorkflowInstance.InstanceId == instanceId) // 1. instanceId is a Guid
{
// copy the output parameters in the specified properties dictionary
Dictionary<string,object>.Enumerator enumerator =
e.OutputParameters.GetEnumerator();
while( enumerator.MoveNext() )
{
KeyValuePair<string,object> pair = enumerator.Current;
if( properties.ContainsKey(pair.Key) )
{
properties[pair.Key] = pair.Value;
}
}
}
};
Exception x = null;
EventHandler<WorkflowTerminatedEventArgs> terminatedHandler = null;
terminatedHandler = delegate(object o, WorkflowTerminatedEventArgs e)
{
if (e.WorkflowInstance.InstanceId == instanceId) // 2. instanceId is a Guid
{
x = e.Exception;
Debug.WriteLine(e.Exception);
}
};
workflowRuntime.WorkflowCompleted += completedHandler;
workflowRuntime.WorkflowTerminated += terminatedHandler;
manualScheduler.RunWorkflow(instance.InstanceId);
// 3. Both delegates are now released
workflowRuntime.WorkflowTerminated -= terminatedHandler;
workflowRuntime.WorkflowCompleted -= completedHandler;
There are two changes – in both delegates, the
instanceId variable is passed, instead of the
instance. Since instanceId is a Guid,
which is a struct type data type, not a class, there’s no
issue of referencing. Structs are copied, not referenced. So, they
don’t leak memory. Secondly, both delegates are
released at the end of the workflow execution, thus releasing both
references.
In Dropthings, I am using the famous CallWorkflow Activity by John Flanders, which
is widely used to execute one Workflow from another synchronously.
There’s a CallWorkflowService class which is
responsible for synchronously executing another workflow and that
has similar memory leak problem. The original code of the service
is as following:
public class CallWorkflowService : WorkflowRuntimeService
{
#region Methods
public void StartWorkflow(Type workflowType,Dictionary<string,object> inparms,
Guid caller,IComparable qn)
{
WorkflowRuntime wr = this.Runtime;
WorkflowInstance wi = wr.CreateWorkflow(workflowType,inparms);
wi.Start();
ManualWorkflowSchedulerService ss =
wr.GetService<ManualWorkflowSchedulerService>();
if (ss != null)
ss.RunWorkflow(wi.InstanceId);
EventHandler<WorkflowCompletedEventArgs> d = null;
d = delegate(object o, WorkflowCompletedEventArgs e)
{
if (e.WorkflowInstance.InstanceId ==wi.InstanceId)
{
wr.WorkflowCompleted -= d;
WorkflowInstance c = wr.GetWorkflow(caller);
c.EnqueueItem(qn, e.OutputParameters, null, null);
}
};
EventHandler<WorkflowTerminatedEventArgs> te = null;
te = delegate(object o, WorkflowTerminatedEventArgs e)
{
if (e.WorkflowInstance.InstanceId == wi.InstanceId)
{
wr.WorkflowTerminated -= te;
WorkflowInstance c = wr.GetWorkflow(caller);
c.EnqueueItem(qn, new Exception("Called Workflow Terminated",
e.Exception), null, null);
}
};
wr.WorkflowCompleted += d;
wr.WorkflowTerminated += te;
}
#endregion Methods
}
As you see, it has that same delegate holding reference to
instance object problem. Moreover, there’s some queue stuff
there, which requires the caller and qn
parameter passed to the StartWorkflow function. So,
not a straight forward fix.
I tried to rewrite the whole CallWorkflowService so
that it does not require two delegates to be created per Workflow.
Then I took the delegates out. Thus there’s no chance of
closure holding reference to unwanted objects. The result looks
like this:
public class CallWorkflowService : WorkflowRuntimeService
{
#region Fields
private EventHandler<WorkflowCompletedEventArgs> _CompletedHandler = null;
private EventHandler<WorkflowTerminatedEventArgs> _TerminatedHandler = null;
private Dictionary<Guid, WorkflowInfo> _WorkflowQueue =
new Dictionary<Guid, WorkflowInfo>();
#endregion Fields
#region Methods
public void StartWorkflow(Type workflowType,Dictionary<string,object> inparms,
Guid caller,IComparable qn)
{
WorkflowRuntime wr = this.Runtime;
WorkflowInstance wi = wr.CreateWorkflow(workflowType,inparms);
wi.Start();
var instanceId = wi.InstanceId;
_WorkflowQueue[instanceId] = new WorkflowInfo { Caller = caller, qn = qn };
ManualWorkflowSchedulerService ss =
wr.GetService<ManualWorkflowSchedulerService>();
if (ss != null)
ss.RunWorkflow(wi.InstanceId);
}
protected override void OnStarted()
{
base.OnStarted();
if (null == _CompletedHandler)
{
_CompletedHandler = delegate(object o, WorkflowCompletedEventArgs e)
{
var instanceId = e.WorkflowInstance.InstanceId;
if (_WorkflowQueue.ContainsKey(instanceId))
{
WorkflowInfo wf = _WorkflowQueue[instanceId];
WorkflowInstance c = this.Runtime.GetWorkflow(wf.Caller);
c.EnqueueItem(wf.qn, e.OutputParameters, null, null);
_WorkflowQueue.Remove(instanceId);
}
};
this.Runtime.WorkflowCompleted += _CompletedHandler;
}
if (null == _TerminatedHandler)
{
_TerminatedHandler = delegate(object o, WorkflowTerminatedEventArgs e)
{
var instanceId = e.WorkflowInstance.InstanceId;
if (_WorkflowQueue.ContainsKey(instanceId))
{
WorkflowInfo wf = _WorkflowQueue[instanceId];
WorkflowInstance c = this.Runtime.GetWorkflow(wf.Caller);
c.EnqueueItem(wf.qn,
new Exception("Called Workflow Terminated", e.Exception),
null, null);
_WorkflowQueue.Remove(instanceId);
}
};
this.Runtime.WorkflowTerminated += _TerminatedHandler;
}
}
protected override void OnStopped()
{
_WorkflowQueue.Clear();
base.OnStopped();
}
#endregion Methods
#region Nested Types
private struct WorkflowInfo
{
#region Fields
public Guid Caller;
public IComparable qn;
#endregion Fields
}
#endregion Nested Types
}
After fixing the problem, another Memory Profile result showed
the leak is gone:

As you see, the numbers vary, which means there’s no
consistent leak. Moreover, looking at the types that remains in
memory, they look more like metadata than instances of
classes. So, they are basically cached instances of metadata,
not instances allocated during workflow execution which are
supposed to be freed. So, we solved the memory leak!
Now you know how to write anonymous delegates without leaking
memory and how to run workflow without leaking them. Basically, the
principle theory is – if you are referencing some outside
object from an anonymous delegate, make sure that
object is not holding reference to the delegate in
some way, may be directly or may be via some child objects of its
own. Because then you have a circular reference. If possible, do
not try to access objects e.g. instance inside an
anonymous delegate that is declared outside the delegate. Try
accessing instrinsic data types like int, string, DateTime, Guid
etc which are not reference type variables. So, instead of
referencing to an object, you should declare local variables e.g.
instanceId that gets the value of properties (e.g.
instance.InstanceId) from the object and then use
those local variables inside the anonymous delegate.